 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Open Must Language Models be to Enable Reliable Scientific Inference?
Mar 27, 2026How does the extent to which a model is open or closed impact the scientific inferences that can be drawn from research that involves it? In this paper, we analyze how restrictions on information about model construction and deployment threaten reliable inference. We argue that current closed models are generally ill-suited for scientific purposes, with some notable exceptions, and discuss ways in which the issues they present to reliable inference can be resolved or mitigated. We recommend that when models are used in research, potential threats to inference should be systematically identified along with the steps taken to mitigate them, and that specific justifications for model selection should be provided.
N-gram-like Language Models Predict Reading Time Best
Mar 10, 2026Recent work has found that contemporary language models such as transformers can become so good at next-word prediction that the probabilities they calculate become worse for predicting reading time. In this paper, we propose that this can be explained by reading time being sensitive to simple n-gram statistics rather than the more complex statistics learned by state-of-the-art transformer language models. We demonstrate that the neural language models whose predictions are most correlated with n-gram probability are also those that calculate probabilities that are the most correlated with eye-tracking-based metrics of reading time on naturalistic text.
Language Statistics and False Belief Reasoning: Evidence from 41 Open-Weight LMs
Feb 17, 2026Research on mental state reasoning in language models (LMs) has the potential to inform theories of human social cognition--such as the theory that mental state reasoning emerges in part from language exposure--and our understanding of LMs themselves. Yet much published work on LMs relies on a relatively small sample of closed-source LMs, limiting our ability to rigorously test psychological theories and evaluate LM capacities. Here, we replicate and extend published work on the false belief task by assessing LM mental state reasoning behavior across 41 open-weight models (from distinct model families). We find sensitivity to implied knowledge states in 34% of the LMs tested; however, consistent with prior work, none fully ``explain away'' the effect in humans. Larger LMs show increased sensitivity and also exhibit higher psychometric predictive power. Finally, we use LM behavior to generate and test a novel hypothesis about human cognition: both humans and LMs show a bias towards attributing false beliefs when knowledge states are cued using a non-factive verb (``John thinks...'') than when cued indirectly (``John looks in the...''). Unlike the primary effect of knowledge states, where human sensitivity exceeds that of LMs, the magnitude of the human knowledge cue effect falls squarely within the distribution of LM effect sizes-suggesting that distributional statistics of language can in principle account for the latter but not the former in humans. These results demonstrate the value of using larger samples of open-weight LMs to test theories of human cognition and evaluate LM capacities.
Not quite Sherlock Holmes: Language model predictions do not reliably differentiate impossible from improbable events
Jun 07, 2025

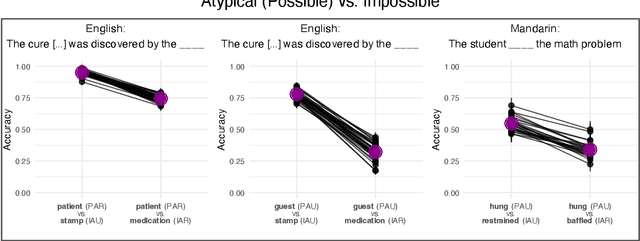

Can language models reliably predict that possible events are more likely than merely improbable ones? By teasing apart possibility, typicality, and contextual relatedness, we show that despite the results of previous work, language models' ability to do this is far from robust. In fact, under certain conditions, all models tested - including Llama 3, Gemma 2, and Mistral NeMo - perform at worse-than-chance level, assigning higher probabilities to impossible sentences such as 'the car was given a parking ticket by the brake' than to merely unlikely sentences such as 'the car was given a parking ticket by the explorer'.
On the Acquisition of Shared Grammatical Representations in Bilingual Language Models
Mar 05, 2025



While crosslingual transfer is crucial to contemporary language models' multilingual capabilities, how it occurs is not well understood. In this paper, we ask what happens to a monolingual language model when it begins to be trained on a second language. Specifically, we train small bilingual models for which we control the amount of data for each language and the order of language exposure. To find evidence of shared multilingual representations, we turn to structural priming, a method used to study grammatical representations in humans. We first replicate previous crosslingual structural priming results and find that after controlling for training data quantity and language exposure, there are asymmetrical effects across language pairs and directions. We argue that this asymmetry may shape hypotheses about human structural priming effects. We also find that structural priming effects are less robust for less similar language pairs, highlighting potential limitations of crosslingual transfer learning and shared representations for typologically diverse languages.
Revenge of the Fallen? Recurrent Models Match Transformers at Predicting Human Language Comprehension Metrics
Apr 30, 2024



Transformers have supplanted Recurrent Neural Networks as the dominant architecture for both natural language processing tasks and, despite criticisms of cognitive implausibility, for modelling the effect of predictability on online human language comprehension. However, two recently developed recurrent neural network architectures, RWKV and Mamba, appear to perform natural language tasks comparably to or better than transformers of equivalent scale. In this paper, we show that contemporary recurrent models are now also able to match - and in some cases, exceed - performance of comparably sized transformers at modeling online human language comprehension. This suggests that transformer language models are not uniquely suited to this task, and opens up new directions for debates about the extent to which architectural features of language models make them better or worse models of human language comprehension.
Structural Priming Demonstrates Abstract Grammatical Representations in Multilingual Language Models
Nov 15, 2023



Abstract grammatical knowledge - of parts of speech and grammatical patterns - is key to the capacity for linguistic generalization in humans. But how abstract is grammatical knowledge in large language models? In the human literature, compelling evidence for grammatical abstraction comes from structural priming. A sentence that shares the same grammatical structure as a preceding sentence is processed and produced more readily. Because confounds exist when using stimuli in a single language, evidence of abstraction is even more compelling from crosslingual structural priming, where use of a syntactic structure in one language primes an analogous structure in another language. We measure crosslingual structural priming in large language models, comparing model behavior to human experimental results from eight crosslingual experiments covering six languages, and four monolingual structural priming experiments in three non-English languages. We find evidence for abstract monolingual and crosslingual grammatical representations in the models that function similarly to those found in humans. These results demonstrate that grammatical representations in multilingual language models are not only similar across languages, but they can causally influence text produced in different languages.
Crosslingual Structural Priming and the Pre-Training Dynamics of Bilingual Language Models
Oct 11, 2023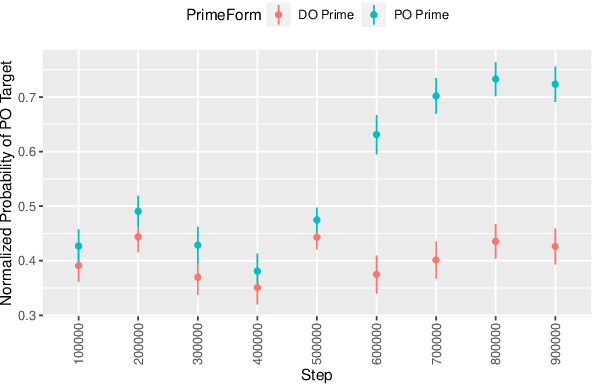
Do multilingual language models share abstract grammatical representations across languages, and if so, when do these develop? Following Sinclair et al. (2022), we use structural priming to test for abstract grammatical representations with causal effects on model outputs. We extend the approach to a Dutch-English bilingual setting, and we evaluate a Dutch-English language model during pre-training. We find that crosslingual structural priming effects emerge early after exposure to the second language, with less than 1M tokens of data in that language. We discuss implications for data contamination, low-resource transfer, and how abstract grammatical representations emerge in multilingual models.
Emergent inabilities? Inverse scaling over the course of pretraining
May 24, 2023
Does inverse scaling only occur as a function of model parameter size, or can it also occur over the course of training? We carry out an exploratory study investigating whether, over the course of training on the language modeling task, the performance of language models at specific tasks can decrease while general performance remains high. We find that for two tasks from the Inverse Scaling Challenge - quote-repetition and redefine-math - this is indeed the case. Specifically, we find that for Pythia (Biderman et al., 2023) models with a higher number of parameters, performance decreases over the course of training at these two tasks, despite these models showing standard (positive) scaling overall. This highlights the importance of testing model performance at all relevant benchmarks any time they are trained on additional data, even if their overall performance improves.
Can Peanuts Fall in Love with Distributional Semantics?
Jan 20, 2023
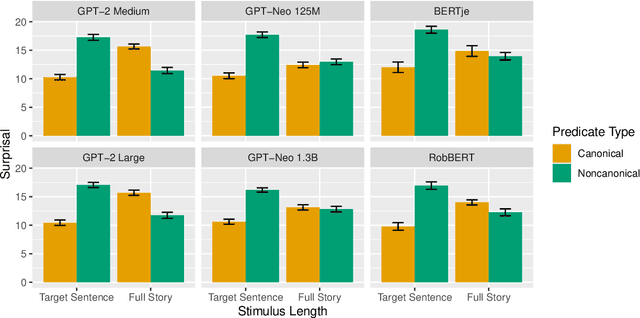
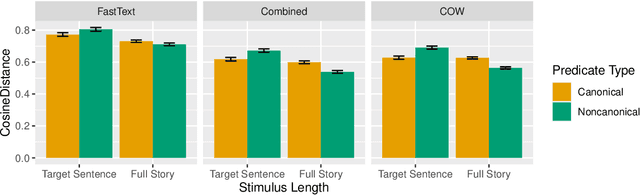
The context in which a sentence appears can drastically alter our expectations about upcoming words - for example, following a short story involving an anthropomorphic peanut, experimental participants are more likely to expect the sentence 'the peanut was in love' than 'the peanut was salted', as indexed by N400 amplitude (Nieuwland & van Berkum, 2006). This rapid and dynamic updating of comprehenders' expectations about the kind of events that a peanut may take part in based on context has been explained using the construct of Situation Models - updated mental representations of key elements of an event under discussion, in this case, the peanut protagonist. However, recent work showing that N400 amplitude can be predicted based on distributional information alone raises the question whether situation models are in fact necessary for the kinds of contextual effects observed in previous work. To investigate this question, we attempt to model the results of Nieuwland and van Berkum (2006) using six computational language models and three sets of word vectors, none of which have explicit situation models or semantic grounding. We find that the effect found by Nieuwland and van Berkum (2006) can be fully modeled by two language models and two sets of word vectors, with others showing a reduced effect. Thus, at least some processing effects normally explained through situation models may not in fact require explicit situation models.