 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Peanuts Fall in Love with Distributional Semantics?
Jan 20, 2023
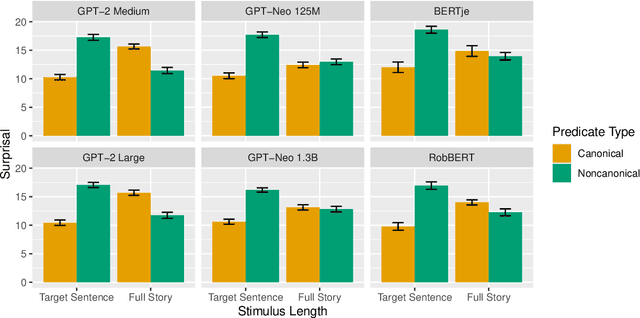
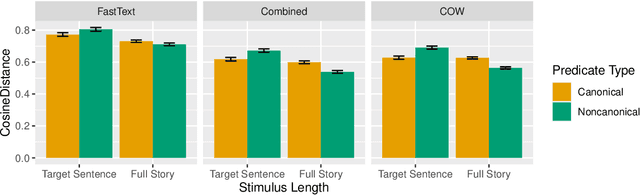
The context in which a sentence appears can drastically alter our expectations about upcoming words - for example, following a short story involving an anthropomorphic peanut, experimental participants are more likely to expect the sentence 'the peanut was in love' than 'the peanut was salted', as indexed by N400 amplitude (Nieuwland & van Berkum, 2006). This rapid and dynamic updating of comprehenders' expectations about the kind of events that a peanut may take part in based on context has been explained using the construct of Situation Models - updated mental representations of key elements of an event under discussion, in this case, the peanut protagonist. However, recent work showing that N400 amplitude can be predicted based on distributional information alone raises the question whether situation models are in fact necessary for the kinds of contextual effects observed in previous work. To investigate this question, we attempt to model the results of Nieuwland and van Berkum (2006) using six computational language models and three sets of word vectors, none of which have explicit situation models or semantic grounding. We find that the effect found by Nieuwland and van Berkum (2006) can be fully modeled by two language models and two sets of word vectors, with others showing a reduced effect. Thus, at least some processing effects normally explained through situation models may not in fact require explicit situation models.
So Cloze yet so Far: N400 Amplitude is Better Predicted by Distributional Information than Human Predictability Judgements
Sep 02, 2021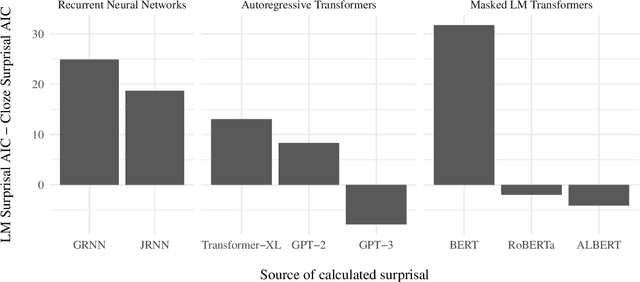
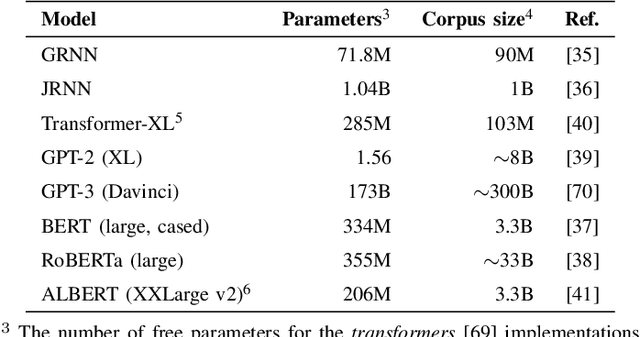
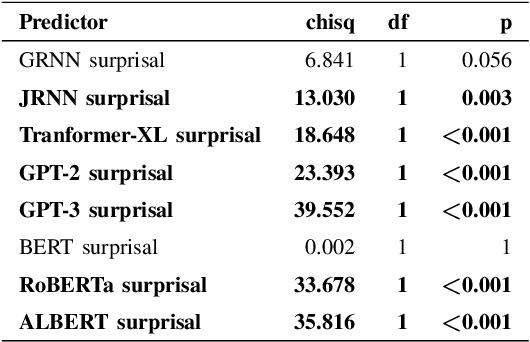
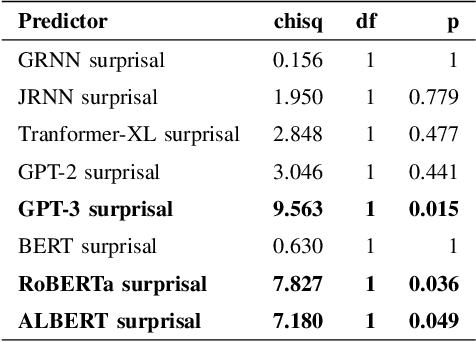
More predictable words are easier to process - they are read faster and elicit smaller neural signals associated with processing difficulty, most notably, the N400 component of the event-related brain potential. Thus, it has been argued that prediction of upcoming words is a key component of language comprehension, and that studying the amplitude of the N400 is a valuable way to investigate the predictions that we make. In this study, we investigate whether the linguistic predictions of computational language models or humans better reflect the way in which natural language stimuli modulate the amplitude of the N400. One important difference in the linguistic predictions of humans versus computational language models is that while language models base their predictions exclusively on the preceding linguistic context, humans may rely on other factors. We find that the predictions of three top-of-the-line contemporary language models - GPT-3, RoBERTa, and ALBERT - match the N400 more closely than human predictions. This suggests that the predictive processes underlying the N400 may be more sensitive to the surface-level statistics of language than previously thought.
Different kinds of cognitive plausibility: why are transformers better than RNNs at predicting N400 amplitude?
Jul 20, 2021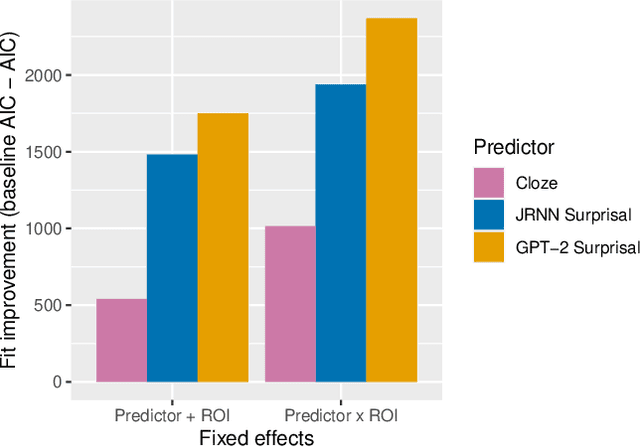
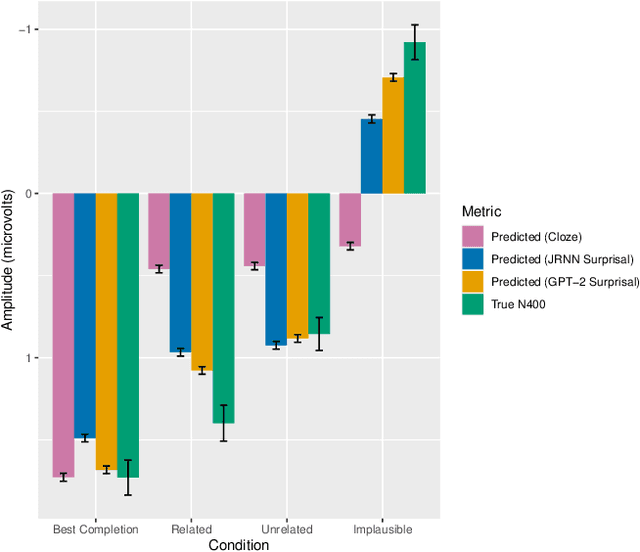
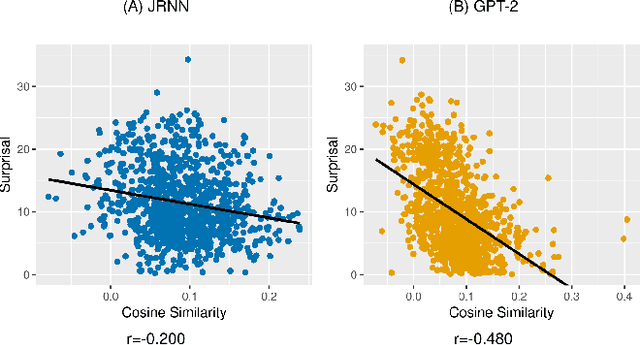
Despite being designed for performance rather than cognitive plausibility, transformer language models have been found to be better at predicting metrics used to assess human language comprehension than language models with other architectures, such as recurrent neural networks. Based on how well they predict the N400, a neural signal associated with processing difficulty, we propose and provide evidence for one possible explanation - their predictions are affected by the preceding context in a way analogous to the effect of semantic facilitation in humans.