 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSo Cloze yet so Far: N400 Amplitude is Better Predicted by Distributional Information than Human Predictability Judgements
Paper and Code
Sep 02, 2021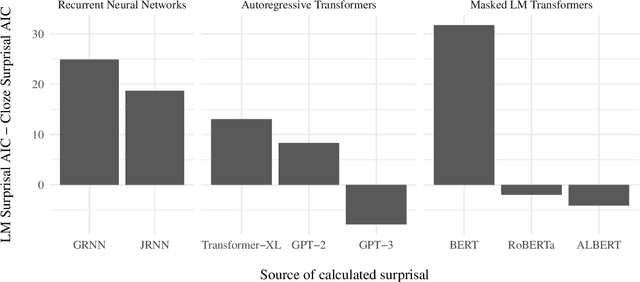
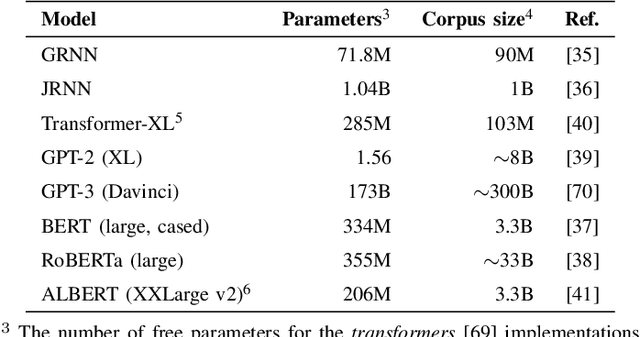
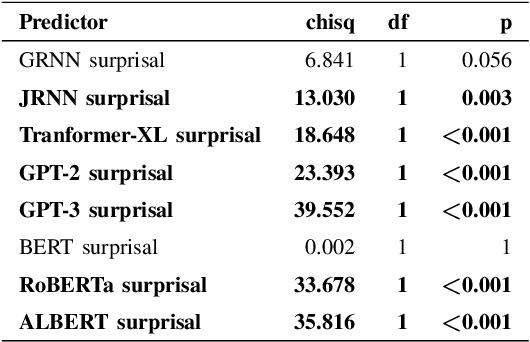
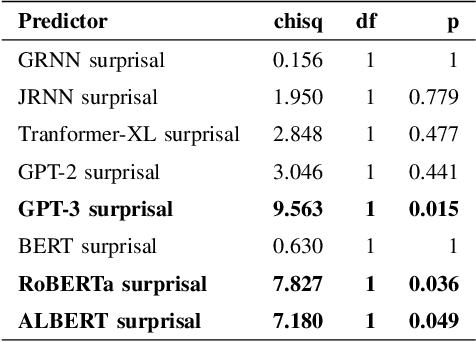
More predictable words are easier to process - they are read faster and elicit smaller neural signals associated with processing difficulty, most notably, the N400 component of the event-related brain potential. Thus, it has been argued that prediction of upcoming words is a key component of language comprehension, and that studying the amplitude of the N400 is a valuable way to investigate the predictions that we make. In this study, we investigate whether the linguistic predictions of computational language models or humans better reflect the way in which natural language stimuli modulate the amplitude of the N400. One important difference in the linguistic predictions of humans versus computational language models is that while language models base their predictions exclusively on the preceding linguistic context, humans may rely on other factors. We find that the predictions of three top-of-the-line contemporary language models - GPT-3, RoBERTa, and ALBERT - match the N400 more closely than human predictions. This suggests that the predictive processes underlying the N400 may be more sensitive to the surface-level statistics of language than previously thought.