 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Modifying the Readability of English Texts with GPT-4
Paper and Code
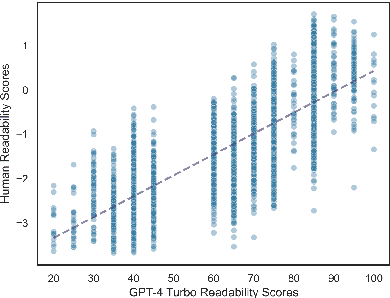
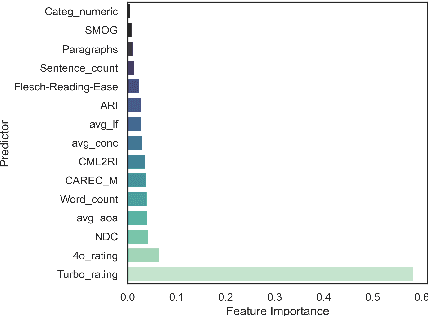
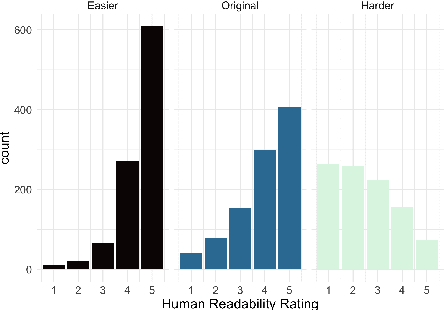
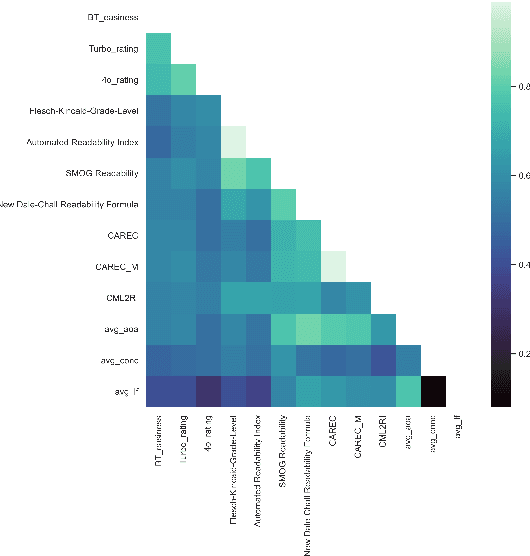
The success of Large Language Models (LLMs) in other domains has raised the question of whether LLMs can reliably assess and manipulate the readability of text. We approach this question empirically. First, using a published corpus of 4,724 English text excerpts, we find that readability estimates produced ``zero-shot'' from GPT-4 Turbo and GPT-4o mini exhibit relatively high correlation with human judgments (r = 0.76 and r = 0.74, respectively), out-performing estimates derived from traditional readability formulas and various psycholinguistic indices. Then, in a pre-registered human experiment (N = 59), we ask whether Turbo can reliably make text easier or harder to read. We find evidence to support this hypothesis, though considerable variance in human judgments remains unexplained. We conclude by discussing the limitations of this approach, including limited scope, as well as the validity of the ``readability'' construct and its dependence on context, audience, and goal.