 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual morphologically-guided tokenization for Latin encoder models
Nov 12, 2025Tokenization is a critical component of language model pretraining, yet standard tokenization methods often prioritize information-theoretical goals like high compression and low fertility rather than linguistic goals like morphological alignment. In fact, they have been shown to be suboptimal for morphologically rich languages, where tokenization quality directly impacts downstream performance. In this work, we investigate morphologically-aware tokenization for Latin, a morphologically rich language that is medium-resource in terms of pretraining data, but high-resource in terms of curated lexical resources -- a distinction that is often overlooked but critical in discussions of low-resource language modeling. We find that morphologically-guided tokenization improves overall performance on four downstream tasks. Performance gains are most pronounced for out of domain texts, highlighting our models' improved generalization ability. Our findings demonstrate the utility of linguistic resources to improve language modeling for morphologically complex languages. For low-resource languages that lack large-scale pretraining data, the development and incorporation of linguistic resources can serve as a feasible alternative to improve LM performance.
Evaluating Morphological Alignment of Tokenizers in 70 Languages
Jul 08, 2025While tokenization is a key step in language modeling, with effects on model training and performance, it remains unclear how to effectively evaluate tokenizer quality. One proposed dimension of tokenizer quality is the extent to which tokenizers preserve linguistically meaningful subwords, aligning token boundaries with morphological boundaries within a word. We expand MorphScore (Arnett & Bergen, 2025), which previously covered 22 languages, to support a total of 70 languages. The updated MorphScore offers more flexibility in evaluation and addresses some of the limitations of the original version. We then correlate our alignment scores with downstream task performance for five pre-trained languages models on seven tasks, with at least one task in each of the languages in our sample. We find that morphological alignment does not explain very much variance in model performance, suggesting that morphological alignment alone does not measure dimensions of tokenization quality relevant to model performance.
BAP v2: An Enhanced Task Framework for Instruction Following in Minecraft Dialogues
Jan 18, 2025
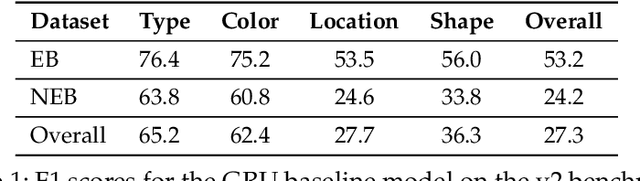


Interactive agents capable of understanding and executing instructions in the physical world have long been a central goal in AI research. The Minecraft Collaborative Building Task (MCBT) provides one such setting to work towards this goal (Narayan-Chen, Jayannavar, and Hockenmaier 2019). It is a two-player game in which an Architect (A) instructs a Builder (B) to construct a target structure in a simulated Blocks World Environment. We focus on the challenging Builder Action Prediction (BAP) subtask of predicting correct action sequences in a given multimodal game context with limited training data (Jayannavar, Narayan-Chen, and Hockenmaier 2020). We take a closer look at evaluation and data for the BAP task, discovering key challenges and making significant improvements on both fronts to propose BAP v2, an upgraded version of the task. This will allow future work to make more efficient and meaningful progress on it. It comprises of: (1) an enhanced evaluation benchmark that includes a cleaner test set and fairer, more insightful metrics, and (2) additional synthetic training data generated from novel Minecraft dialogue and target structure simulators emulating the MCBT. We show that the synthetic data can be used to train more performant and robust neural models even with relatively simple training methods. Looking ahead, such data could also be crucial for training more sophisticated, data-hungry deep transformer models and training/fine-tuning increasingly large LLMs. Although modeling is not the primary focus of this work, we also illustrate the impact of our data and training methodologies on a simple LLM- and transformer-based model, thus validating the robustness of our approach, and setting the stage for more advanced architectures and LLMs going forward.
Latin Treebanks in Review: An Evaluation of Morphological Tagging Across Time
Aug 13, 2024
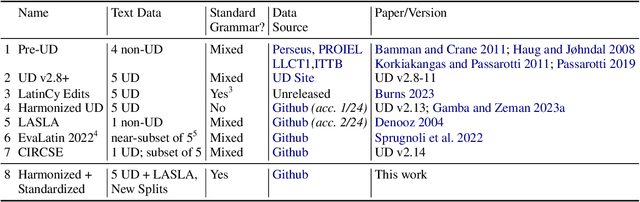

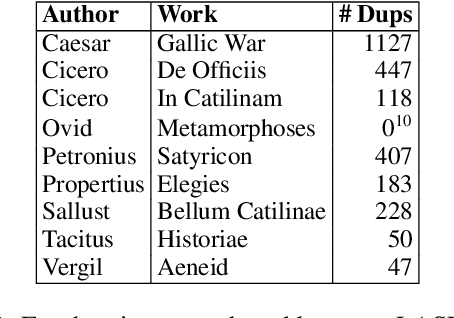
Existing Latin treebanks draw from Latin's long written tradition, spanning 17 centuries and a variety of cultures. Recent efforts have begun to harmonize these treebanks' annotations to better train and evaluate morphological taggers. However, the heterogeneity of these treebanks must be carefully considered to build effective and reliable data. In this work, we review existing Latin treebanks to identify the texts they draw from, identify their overlap, and document their coverage across time and genre. We additionally design automated conversions of their morphological feature annotations into the conventions of standard Latin grammar. From this, we build new time-period data splits that draw from the existing treebanks which we use to perform a broad cross-time analysis for POS and morphological feature tagging. We find that BERT-based taggers outperform existing taggers while also being more robust to cross-domain shifts.
Effects of Interfaces on Human-Robot Trust: Specifying and Visualizing Physical Zones
Dec 01, 2021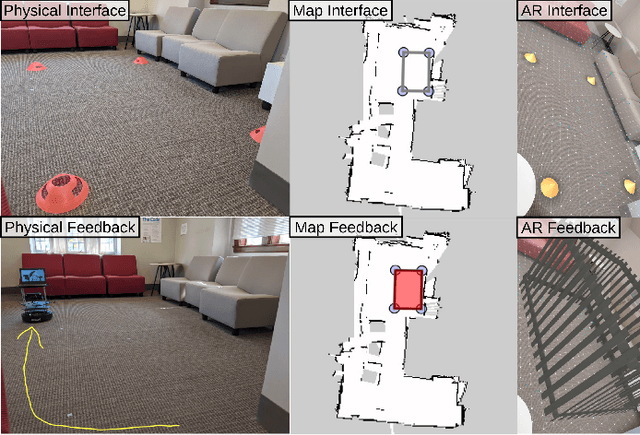

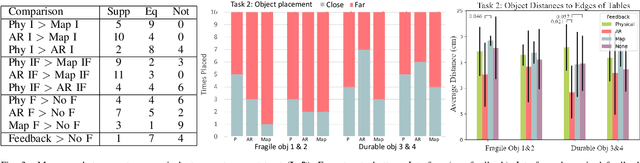

In this paper we investigate the influence interfaces and feedback have on human-robot trust levels when operating in a shared physical space. The task we use is specifying a "no-go" region for a robot in an indoor environment. We evaluate three styles of interface (physical, AR, and map-based) and four feedback mechanisms (no feedback, robot drives around the space, an AR "fence", and the region marked on the map). Our evaluation looks at both usability and trust. Specifically, if the participant trusts that the robot "knows" where the no-go region is and their confidence in the robot's ability to avoid that region. We use both self-reported and indirect measures of trust and usability. Our key findings are: 1) interfaces and feedback do influence levels of trust; 2) the participants largely preferred a mixed interface-feedback pair, where the modality for the interface differed from the feedback.