 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training
Sep 06, 2024Language models can largely benefit from efficient tokenization. However, they still mostly utilize the classical BPE algorithm, a simple and reliable method. This has been shown to cause such issues as under-trained tokens and sub-optimal compression that may affect the downstream performance. We introduce Picky BPE, a modified BPE algorithm that carries out vocabulary refinement during tokenizer training. Our method improves vocabulary efficiency, eliminates under-trained tokens, and does not compromise text compression. Our experiments show that our method does not reduce the downstream performance, and in several cases improves it.
Beyond Toxic: Toxicity Detection Datasets are Not Enough for Brand Safety
Mar 27, 2023

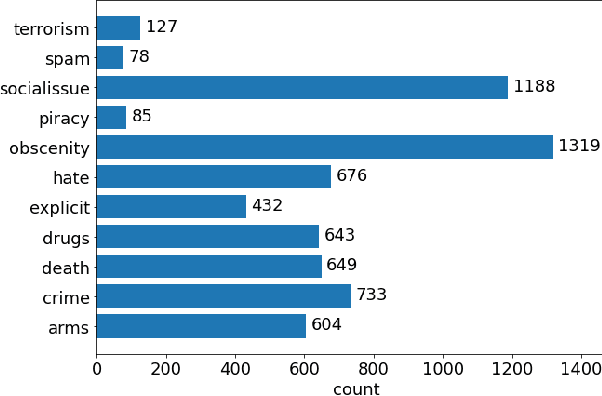

The rapid growth in user generated content on social media has resulted in a significant rise in demand for automated content moderation. Various methods and frameworks have been proposed for the tasks of hate speech detection and toxic comment classification. In this work, we combine common datasets to extend these tasks to brand safety. Brand safety aims to protect commercial branding by identifying contexts where advertisements should not appear and covers not only toxicity, but also other potentially harmful content. As these datasets contain different label sets, we approach the overall problem as a binary classification task. We demonstrate the need for building brand safety specific datasets via the application of common toxicity detection datasets to a subset of brand safety and empirically analyze the effects of weighted sampling strategies in text classification.
Translation Transformers Rediscover Inherent Data Domains
Sep 16, 2021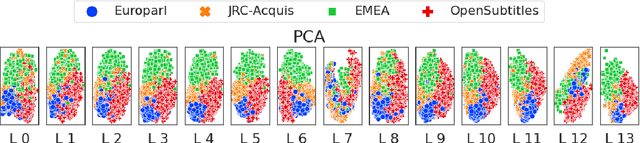

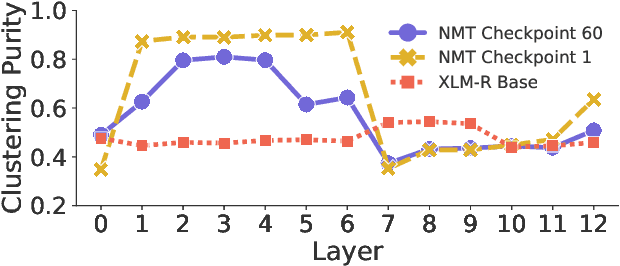
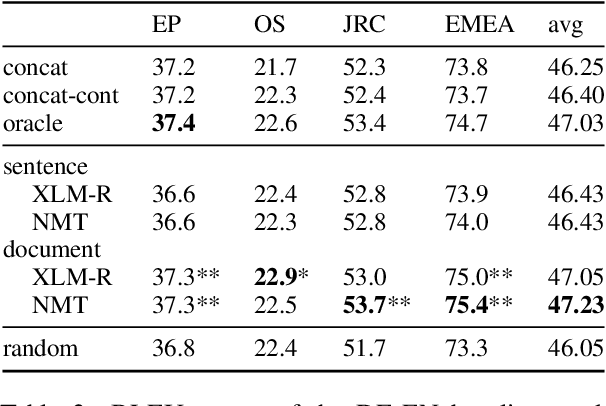
Many works proposed methods to improve the performance of Neural Machine Translation (NMT) models in a domain/multi-domain adaptation scenario. However, an understanding of how NMT baselines represent text domain information internally is still lacking. Here we analyze the sentence representations learned by NMT Transformers and show that these explicitly include the information on text domains, even after only seeing the input sentences without domains labels. Furthermore, we show that this internal information is enough to cluster sentences by their underlying domains without supervision. We show that NMT models produce clusters better aligned to the actual domains compared to pre-trained language models (LMs). Notably, when computed on document-level, NMT cluster-to-domain correspondence nears 100%. We use these findings together with an approach to NMT domain adaptation using automatically extracted domains. Whereas previous work relied on external LMs for text clustering, we propose re-using the NMT model as a source of unsupervised clusters. We perform an extensive experimental study comparing two approaches across two data scenarios, three language pairs, and both sentence-level and document-level clustering, showing equal or significantly superior performance compared to LMs.
Grammatical Error Correction and Style Transfer via Zero-shot Monolingual Translation
Mar 27, 2019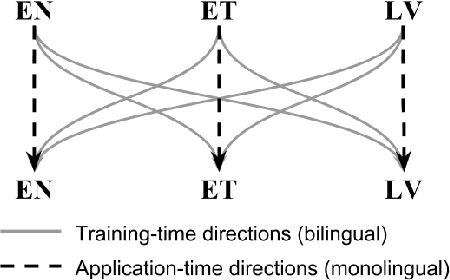
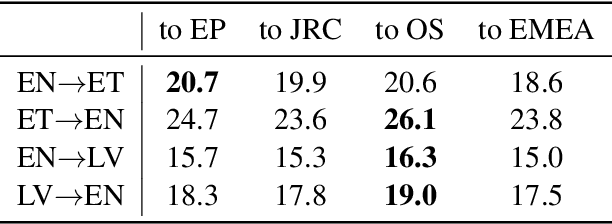
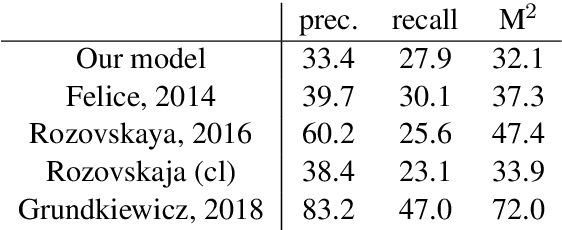
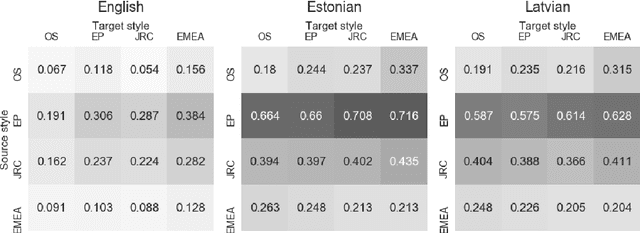
Both grammatical error correction and text style transfer can be viewed as monolingual sequence-to-sequence transformation tasks, but the scarcity of directly annotated data for either task makes them unfeasible for most languages. We present an approach that does both tasks within the same trained model, and only uses regular language parallel data, without requiring error-corrected or style-adapted texts. We apply our model to three languages and present a thorough evaluation on both tasks, showing that the model is reliable for a number of error types and style transfer aspects.
Monolingual and Cross-lingual Zero-shot Style Transfer
Aug 01, 2018
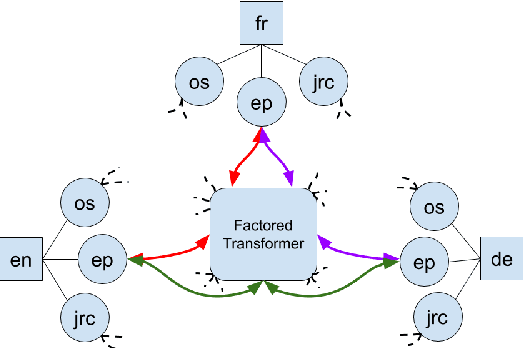

We introduce the task of zero-shot style transfer between different languages. Our training data includes multilingual parallel corpora, but does not contain any parallel sentences between styles, similarly to the recent previous work. We propose a unified multilingual multi-style machine translation system design, that allows to perform zero-shot style conversions during inference; moreover, it does so both monolingually and cross-lingually. Our model allows to increase the presence of dissimilar styles in corpus by up to 3 times, easily learns to operate with various contractions, and provides reasonable lexicon swaps as we see from manual evaluation.