 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Err Is Human, but Llamas Can Learn It Too
Mar 08, 2024



This study explores enhancing grammatical error correction (GEC) through artificial error generation (AEG) using language models (LMs). Specifically, we fine-tune Llama 2-based LMs for error generation and find that this approach yields synthetic errors akin to human errors. Next, we train GEC Llama models with the help of these artificial errors and outperform previous state-of-the-art error correction models, with gains ranging between 0.8 and 6 F0.5 points across all tested languages (German, Ukrainian, and Estonian). Moreover, we demonstrate that generating errors by fine-tuning smaller sequence-to-sequence models and prompting large commercial LMs (GPT-3.5 and GPT-4) also results in synthetic errors beneficially affecting error generation models.
True Detective: A Challenging Benchmark for Deep Abductive Reasoning \\in Foundation Models
Dec 20, 2022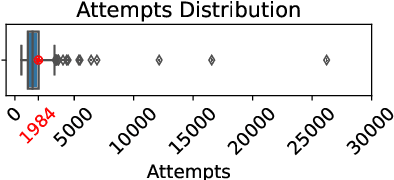
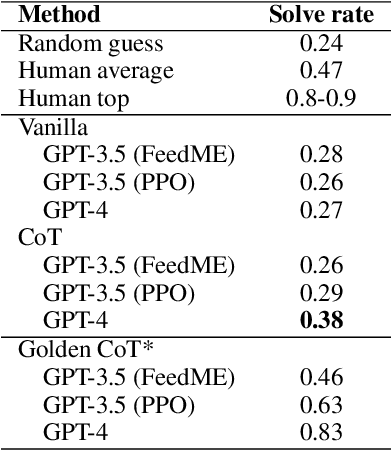
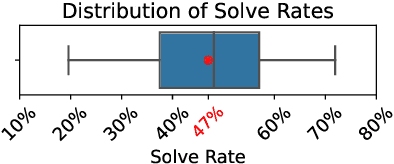

Large language models (LLMs) have demonstrated strong performance in zero-shot reasoning tasks, including abductive reasoning. This is reflected in their ability to perform well on current benchmarks in this area. However, to truly test the limits of LLMs in abductive reasoning, a more challenging benchmark is needed. In this paper, we present such a benchmark, consisting of 191 long-form mystery stories, each approximately 1200 words in length and presented in the form of detective puzzles. Each puzzle includes a multiple-choice question for evaluation sourced from the "5 Minute Mystery" platform. Our results show that state-of-the-art GPT models perform significantly worse than human solvers on this benchmark, with an accuracy of 28\% compared to 47\% for humans. This indicates that there is still a significant gap in the abductive reasoning abilities of LLMs and highlights the need for further research in this area. Our work provides a challenging benchmark for future studies on reasoning in language models and contributes to a better understanding of the limits of LLMs' abilities.
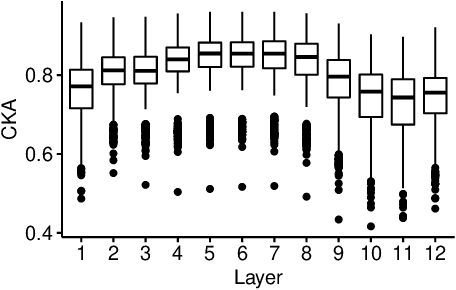
Cross-lingual Similarity of Multilingual Representations Revisited
Dec 04, 2022Related works used indexes like CKA and variants of CCA to measure the similarity of cross-lingual representations in multilingual language models. In this paper, we argue that assumptions of CKA/CCA align poorly with one of the motivating goals of cross-lingual learning analysis, i.e., explaining zero-shot cross-lingual transfer. We highlight what valuable aspects of cross-lingual similarity these indexes fail to capture and provide a motivating case study \textit{demonstrating the problem empirically}. Then, we introduce \textit{Average Neuron-Wise Correlation (ANC)} as a straightforward alternative that is exempt from the difficulties of CKA/CCA and is good specifically in a cross-lingual context. Finally, we use ANC to construct evidence that the previously introduced ``first align, then predict'' pattern takes place not only in masked language models (MLMs) but also in multilingual models with \textit{causal language modeling} objectives (CLMs). Moreover, we show that the pattern extends to the \textit{scaled versions} of the MLMs and CLMs (up to 85x original mBERT).\footnote{Our code is publicly available at \url{https://github.com/TartuNLP/xsim}}
* Accepted at AACL 2022
Establishing Interlingua in Multilingual Language Models
Sep 16, 2021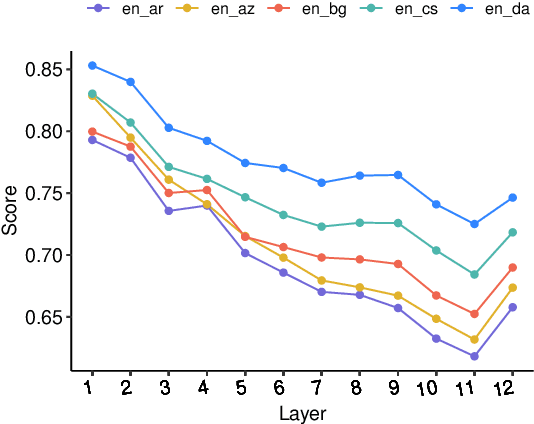


Large multilingual language models show remarkable zero-shot cross-lingual transfer performance on a range of tasks. Follow-up works hypothesized that these models internally project representations of different languages into a shared interlingual space. However, they produced contradictory results. In this paper, we correct the famous prior work claiming that "BERT is not an Interlingua" and show that with the proper choice of sentence representation different languages actually do converge to a shared space in such language models. Furthermore, we demonstrate that this convergence pattern is robust across four measures of correlation similarity and six mBERT-like models. We then extend our analysis to 28 diverse languages and find that the interlingual space exhibits a particular structure similar to the linguistic relatedness of languages. We also highlight a few outlier languages that seem to fail to converge to the shared space. The code for replicating our results is available at the following URL: https://github.com/maksym-del/interlingua.
Translation Transformers Rediscover Inherent Data Domains
Sep 16, 2021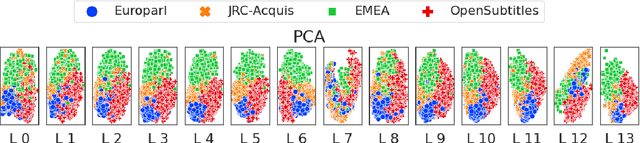

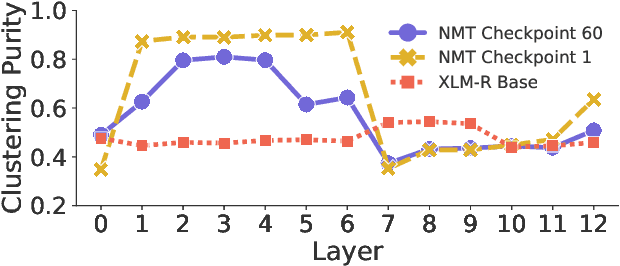
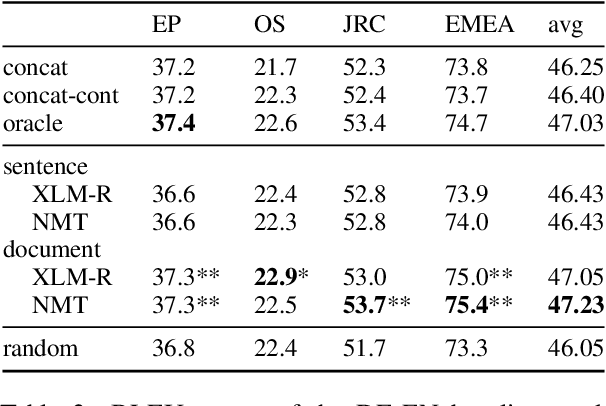
Many works proposed methods to improve the performance of Neural Machine Translation (NMT) models in a domain/multi-domain adaptation scenario. However, an understanding of how NMT baselines represent text domain information internally is still lacking. Here we analyze the sentence representations learned by NMT Transformers and show that these explicitly include the information on text domains, even after only seeing the input sentences without domains labels. Furthermore, we show that this internal information is enough to cluster sentences by their underlying domains without supervision. We show that NMT models produce clusters better aligned to the actual domains compared to pre-trained language models (LMs). Notably, when computed on document-level, NMT cluster-to-domain correspondence nears 100%. We use these findings together with an approach to NMT domain adaptation using automatically extracted domains. Whereas previous work relied on external LMs for text clustering, we propose re-using the NMT model as a source of unsupervised clusters. We perform an extensive experimental study comparing two approaches across two data scenarios, three language pairs, and both sentence-level and document-level clustering, showing equal or significantly superior performance compared to LMs.
Grammatical Error Correction and Style Transfer via Zero-shot Monolingual Translation
Mar 27, 2019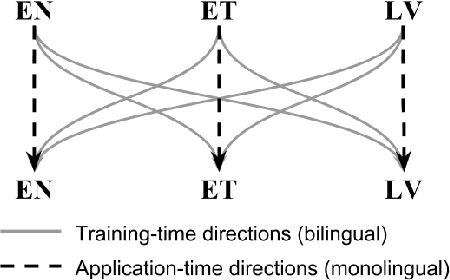
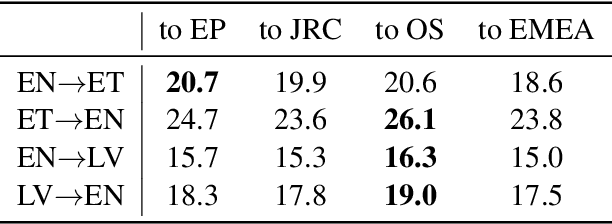
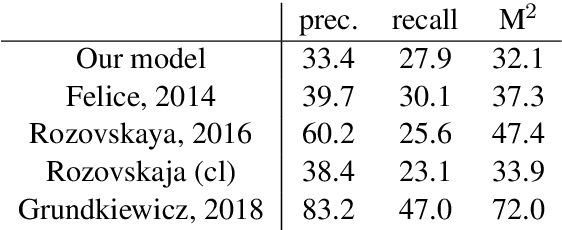
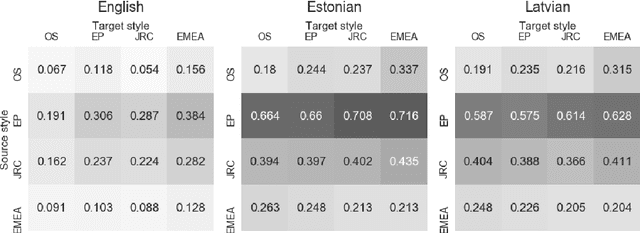
Both grammatical error correction and text style transfer can be viewed as monolingual sequence-to-sequence transformation tasks, but the scarcity of directly annotated data for either task makes them unfeasible for most languages. We present an approach that does both tasks within the same trained model, and only uses regular language parallel data, without requiring error-corrected or style-adapted texts. We apply our model to three languages and present a thorough evaluation on both tasks, showing that the model is reliable for a number of error types and style transfer aspects.
Monolingual and Cross-lingual Zero-shot Style Transfer
Aug 01, 2018
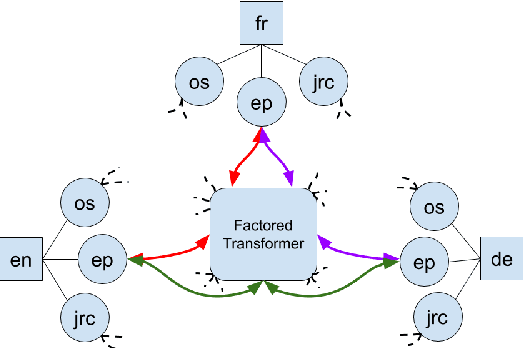

We introduce the task of zero-shot style transfer between different languages. Our training data includes multilingual parallel corpora, but does not contain any parallel sentences between styles, similarly to the recent previous work. We propose a unified multilingual multi-style machine translation system design, that allows to perform zero-shot style conversions during inference; moreover, it does so both monolingually and cross-lingually. Our model allows to increase the presence of dissimilar styles in corpus by up to 3 times, easily learns to operate with various contractions, and provides reasonable lexicon swaps as we see from manual evaluation.