Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammatical Error Correction and Style Transfer via Zero-shot Monolingual Translation
Paper and Code
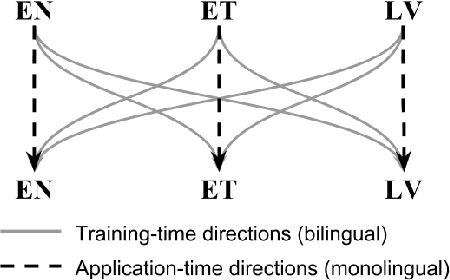
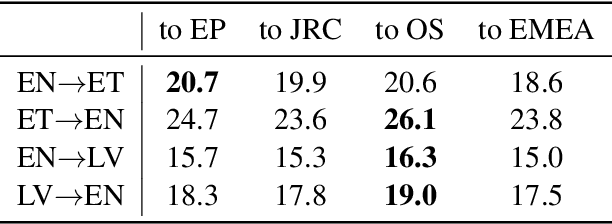
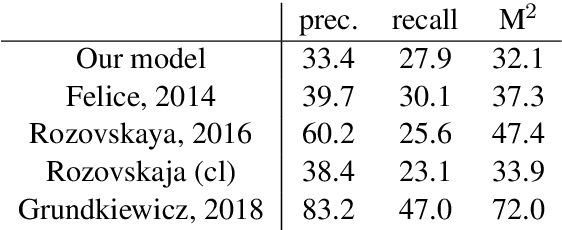
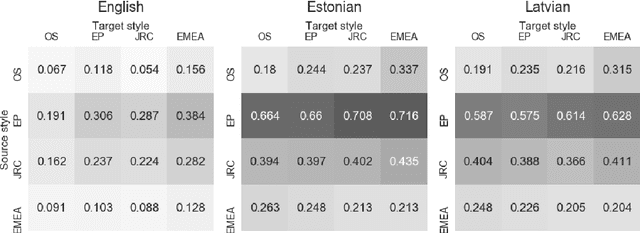
Both grammatical error correction and text style transfer can be viewed as monolingual sequence-to-sequence transformation tasks, but the scarcity of directly annotated data for either task makes them unfeasible for most languages. We present an approach that does both tasks within the same trained model, and only uses regular language parallel data, without requiring error-corrected or style-adapted texts. We apply our model to three languages and present a thorough evaluation on both tasks, showing that the model is reliable for a number of error types and style transfer aspects.
View paper on