 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutocorrect for Estonian texts: final report from project EKTB25
Feb 18, 2024The project was funded in 2021-2023 by the National Programme of Estonian Language Technology. Its main aim was to develop spelling and grammar correction tools for the Estonian language. The main challenge was the very small amount of available error correction data needed for such development. To mitigate this, (1) we annotated more correction data for model training and testing, (2) we tested transfer-learning, i.e. retraining machine learning models created for other tasks, so as not to depend solely on correction data, (3) we compared the developed method and model with alternatives, including large language models. We also developed automatic evaluation, which can calculate the accuracy and yield of corrections by error category, so that the effectiveness of different methods can be compared in detail. There has been a breakthrough in large language models during the project: GPT4, a commercial language model with Estonian-language support, has been created. We took into account the existence of the model when adjusting plans and in the report we present a comparison with the ability of GPT4 to improve the Estonian language text. The final results show that the approach we have developed provides better scores than GPT4 and the result is usable but not entirely reliable yet. The report also contains ideas on how GPT4 and other major language models can be implemented in the future, focusing on open-source solutions. All results of this project are open-data/open-source, with licenses that allow them to be used for purposes including commercial ones.
Grammatical Error Correction and Style Transfer via Zero-shot Monolingual Translation
Mar 27, 2019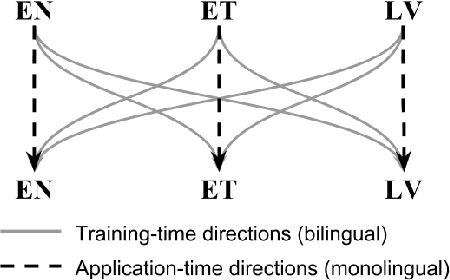
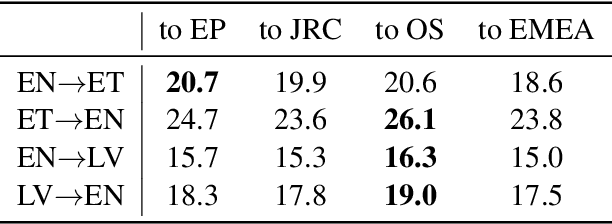
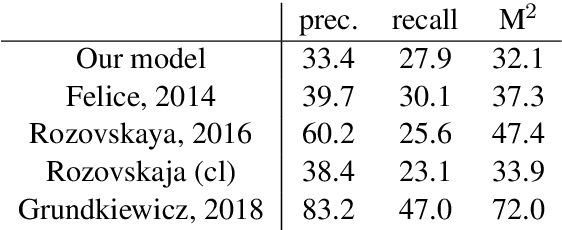
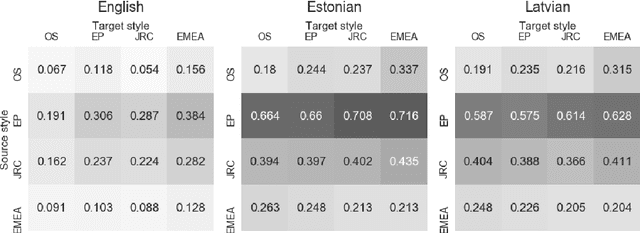
Both grammatical error correction and text style transfer can be viewed as monolingual sequence-to-sequence transformation tasks, but the scarcity of directly annotated data for either task makes them unfeasible for most languages. We present an approach that does both tasks within the same trained model, and only uses regular language parallel data, without requiring error-corrected or style-adapted texts. We apply our model to three languages and present a thorough evaluation on both tasks, showing that the model is reliable for a number of error types and style transfer aspects.