 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Toxic: Toxicity Detection Datasets are Not Enough for Brand Safety
Mar 27, 2023

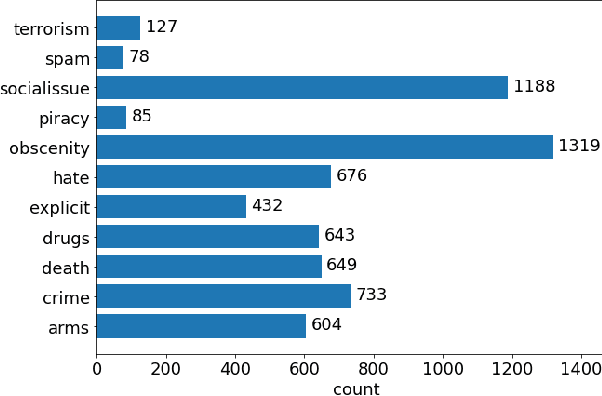

The rapid growth in user generated content on social media has resulted in a significant rise in demand for automated content moderation. Various methods and frameworks have been proposed for the tasks of hate speech detection and toxic comment classification. In this work, we combine common datasets to extend these tasks to brand safety. Brand safety aims to protect commercial branding by identifying contexts where advertisements should not appear and covers not only toxicity, but also other potentially harmful content. As these datasets contain different label sets, we approach the overall problem as a binary classification task. We demonstrate the need for building brand safety specific datasets via the application of common toxicity detection datasets to a subset of brand safety and empirically analyze the effects of weighted sampling strategies in text classification.
Scaling Cross-Domain Content-Based Image Retrieval for E-commerce Snap and Search Application
Apr 13, 2022

In this industry talk at ECIR 2022, we illustrate how we approach the main challenges from large scale cross-domain content-based image retrieval using a cascade method and a combination of our visual search and classification capabilities. Specifically, we present a system that is able to handle the scale of the data for e-commerce usage and the cross-domain nature of the query and gallery image pools. We showcase the approach applied in real-world e-commerce snap and search use case and its impact on ranking and latency performance.