 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividuation in Neural Models with and without Visual Grounding
Sep 27, 2024We show differences between a language-and-vision model CLIP and two text-only models - FastText and SBERT - when it comes to the encoding of individuation information. We study latent representations that CLIP provides for substrates, granular aggregates, and various numbers of objects. We demonstrate that CLIP embeddings capture quantitative differences in individuation better than models trained on text-only data. Moreover, the individuation hierarchy we deduce from the CLIP embeddings agrees with the hierarchies proposed in linguistics and cognitive science.
PLUGH: A Benchmark for Spatial Understanding and Reasoning in Large Language Models
Aug 03, 2024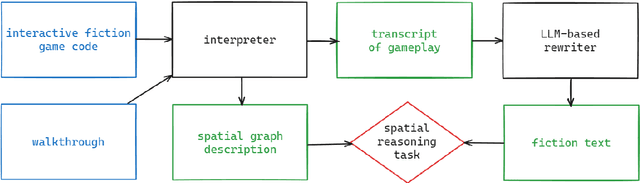
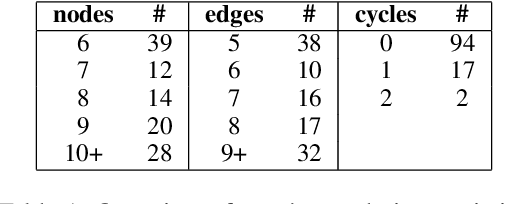
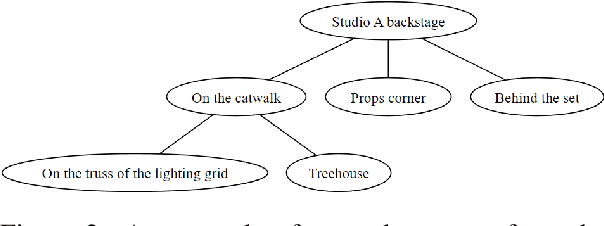
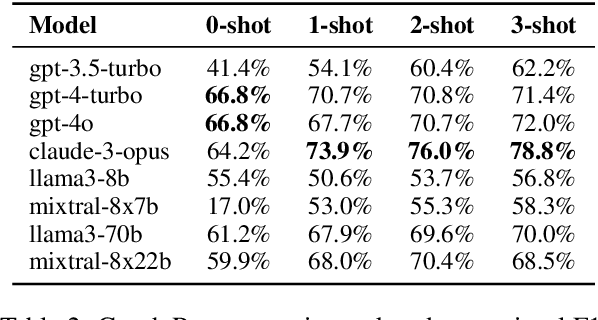
We present PLUGH (https://www.urbandictionary.com/define.php?term=plugh), a modern benchmark that currently consists of 5 tasks, each with 125 input texts extracted from 48 different games and representing 61 different (non-isomorphic) spatial graphs to assess the abilities of Large Language Models (LLMs) for spatial understanding and reasoning. Our evaluation of API-based and open-sourced LLMs shows that while some commercial LLMs exhibit strong reasoning abilities, open-sourced competitors can demonstrate almost the same level of quality; however, all models still have significant room for improvement. We identify typical reasons for LLM failures and discuss possible ways to deal with them. Datasets and evaluation code are released (https://github.com/altsoph/PLUGH).
Machine Apophenia: The Kaleidoscopic Generation of Architectural Images
Jul 12, 2024This study investigates the application of generative artificial intelligence in architectural design. We present a novel methodology that combines multiple neural networks to create an unsupervised and unmoderated stream of unique architectural images. Our approach is grounded in the conceptual framework called machine apophenia. We hypothesize that neural networks, trained on diverse human-generated data, internalize aesthetic preferences and tend to produce coherent designs even from random inputs. The methodology involves an iterative process of image generation, description, and refinement, resulting in captioned architectural postcards automatically shared on several social media platforms. Evaluation and ablation studies show the improvement both in technical and aesthetic metrics of resulting images on each step.
Humor Mechanics: Advancing Humor Generation with Multistep Reasoning
May 12, 2024
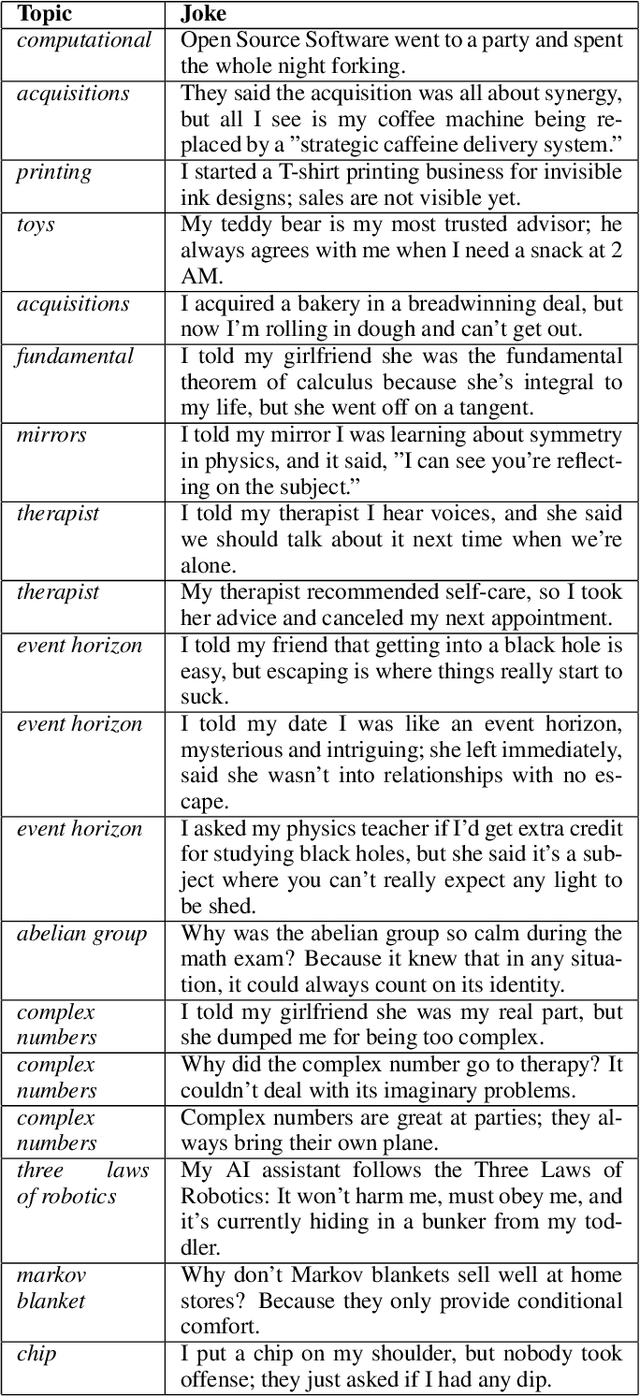


In this paper, we explore the generation of one-liner jokes through multi-step reasoning. Our work involved reconstructing the process behind creating humorous one-liners and developing a working prototype for humor generation. We conducted comprehensive experiments with human participants to evaluate our approach, comparing it with human-created jokes, zero-shot GPT-4 generated humor, and other baselines. The evaluation focused on the quality of humor produced, using human labeling as a benchmark. Our findings demonstrate that the multi-step reasoning approach consistently improves the quality of generated humor. We present the results and share the datasets used in our experiments, offering insights into enhancing humor generation with artificial intelligence.
Branching Narratives: Character Decision Points Detection
May 12, 2024

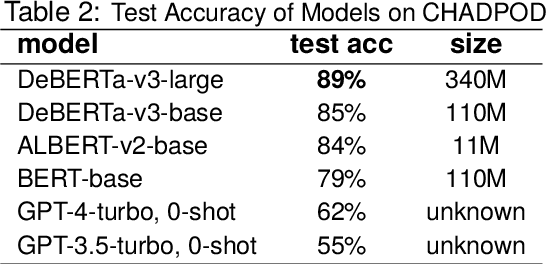
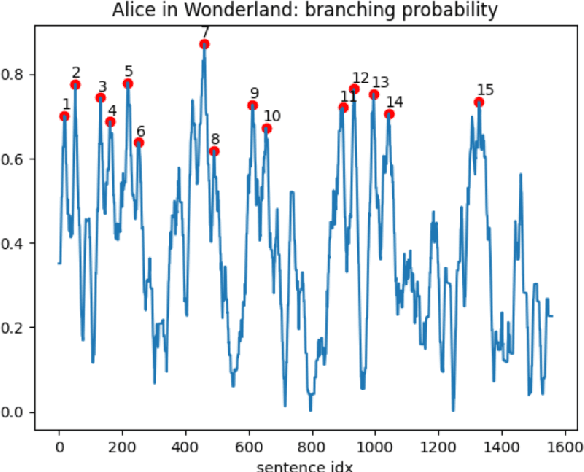
This paper presents the Character Decision Points Detection (CHADPOD) task, a task of identification of points within narratives where characters make decisions that may significantly influence the story's direction. We propose a novel dataset based on CYOA-like games graphs to be used as a benchmark for such a task. We provide a comparative analysis of different models' performance on this task, including a couple of LLMs and several MLMs as baselines, achieving up to 89% accuracy. This underscores the complexity of narrative analysis, showing the challenges associated with understanding character-driven story dynamics. Additionally, we show how such a model can be applied to the existing text to produce linear segments divided by potential branching points, demonstrating the practical application of our findings in narrative analysis.
Knowledge Graph Representation for Political Information Sources
Apr 04, 2024With the rise of computational social science, many scholars utilize data analysis and natural language processing tools to analyze social media, news articles, and other accessible data sources for examining political and social discourse. Particularly, the study of the emergence of echo-chambers due to the dissemination of specific information has become a topic of interest in mixed methods research areas. In this paper, we analyze data collected from two news portals, Breitbart News (BN) and New York Times (NYT) to prove the hypothesis that the formation of echo-chambers can be partially explained on the level of an individual information consumption rather than a collective topology of individuals' social networks. Our research findings are presented through knowledge graphs, utilizing a dataset spanning 11.5 years gathered from BN and NYT media portals. We demonstrate that the application of knowledge representation techniques to the aforementioned news streams highlights, contrary to common assumptions, shows relative "internal" neutrality of both sources and polarizing attitude towards a small fraction of entities. Additionally, we argue that such characteristics in information sources lead to fundamental disparities in audience worldviews, potentially acting as a catalyst for the formation of echo-chambers.
Unrolling Virtual Worlds for Immersive Experiences
Nov 14, 2023This research pioneers a method for generating immersive worlds, drawing inspiration from elements of vintage adventure games like Myst and employing modern text-to-image models. We explore the intricate conversion of 2D panoramas into 3D scenes using equirectangular projections, addressing the distortions in perception that occur as observers navigate within the encompassing sphere. Our approach employs a technique similar to "inpainting" to rectify distorted projections, enabling the smooth construction of locally coherent worlds. This provides extensive insight into the interrelation of technology, perception, and experiential reality within human-computer interaction.
Post Turing: Mapping the landscape of LLM Evaluation
Nov 03, 2023In the rapidly evolving landscape of Large Language Models (LLMs), introduction of well-defined and standardized evaluation methodologies remains a crucial challenge. This paper traces the historical trajectory of LLM evaluations, from the foundational questions posed by Alan Turing to the modern era of AI research. We categorize the evolution of LLMs into distinct periods, each characterized by its unique benchmarks and evaluation criteria. As LLMs increasingly mimic human-like behaviors, traditional evaluation proxies, such as the Turing test, have become less reliable. We emphasize the pressing need for a unified evaluation system, given the broader societal implications of these models. Through an analysis of common evaluation methodologies, we advocate for a qualitative shift in assessment approaches, underscoring the importance of standardization and objective criteria. This work serves as a call for the AI community to collaboratively address the challenges of LLM evaluation, ensuring their reliability, fairness, and societal benefit.
BERT in Plutarch's Shadows
Nov 10, 2022
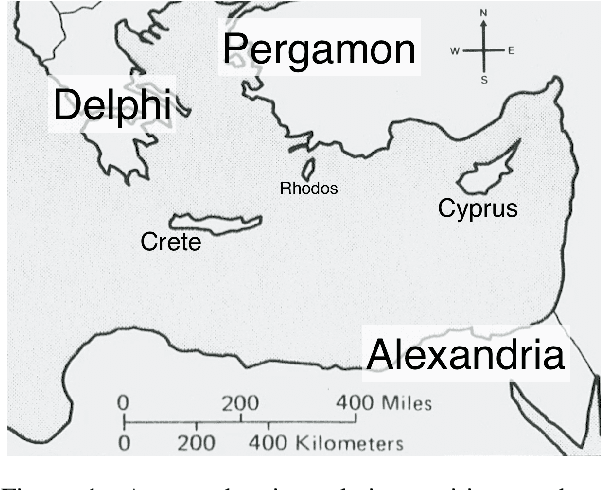

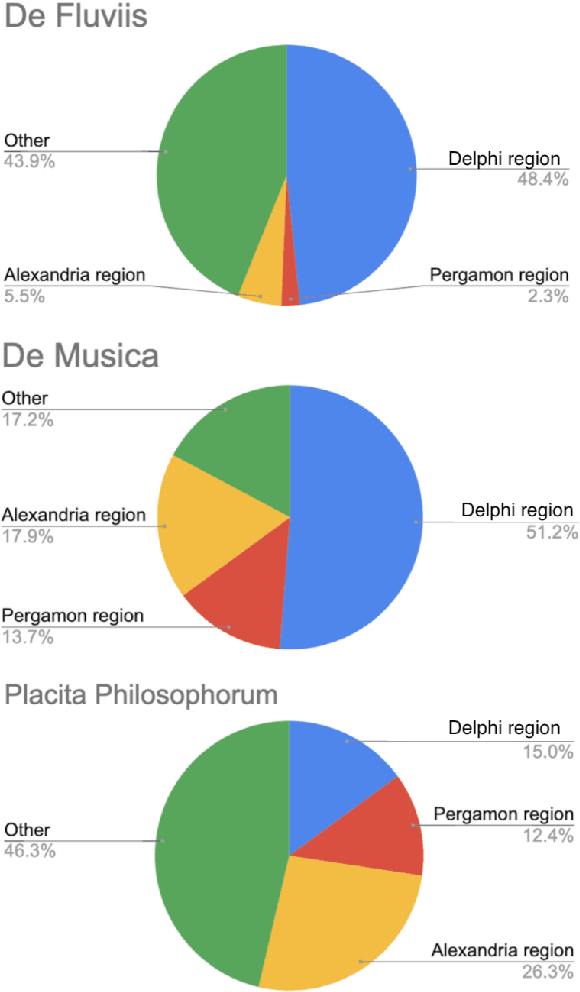
The extensive surviving corpus of the ancient scholar Plutarch of Chaeronea (ca. 45-120 CE) also contains several texts which, according to current scholarly opinion, did not originate with him and are therefore attributed to an anonymous author Pseudo-Plutarch. These include, in particular, the work Placita Philosophorum (Quotations and Opinions of the Ancient Philosophers), which is extremely important for the history of ancient philosophy. Little is known about the identity of that anonymous author and its relation to other authors from the same period. This paper presents a BERT language model for Ancient Greek. The model discovers previously unknown statistical properties relevant to these literary, philosophical, and historical problems and can shed new light on this authorship question. In particular, the Placita Philosophorum, together with one of the other Pseudo-Plutarch texts, shows similarities with the texts written by authors from an Alexandrian context (2nd/3rd century CE).
What is Wrong with Language Models that Can Not Tell a Story?
Nov 10, 2022This paper argues that a deeper understanding of narrative and the successful generation of longer subjectively interesting texts is a vital bottleneck that hinders the progress in modern Natural Language Processing (NLP) and may even be in the whole field of Artificial Intelligence. We demonstrate that there are no adequate datasets, evaluation methods, and even operational concepts that could be used to start working on narrative processing.