 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUGH: A Benchmark for Spatial Understanding and Reasoning in Large Language Models
Paper and Code
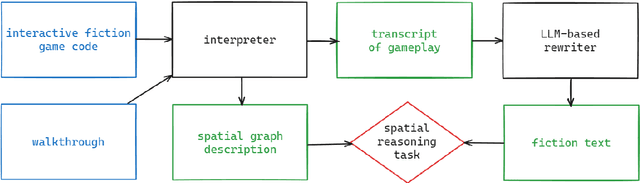
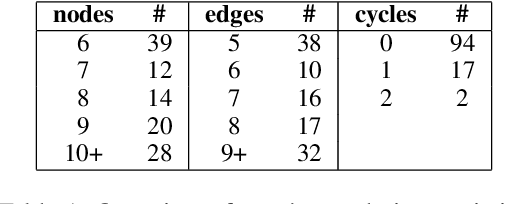
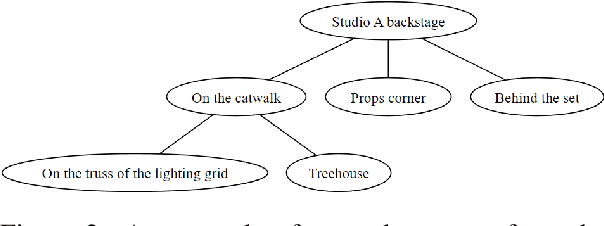
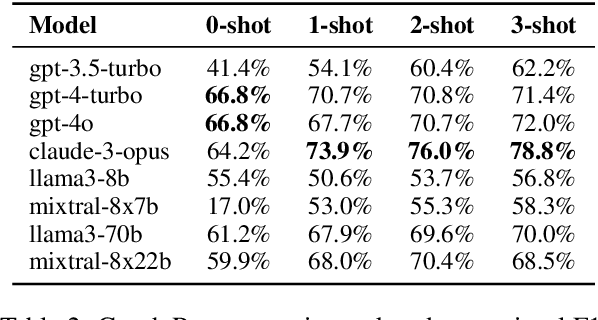
We present PLUGH (https://www.urbandictionary.com/define.php?term=plugh), a modern benchmark that currently consists of 5 tasks, each with 125 input texts extracted from 48 different games and representing 61 different (non-isomorphic) spatial graphs to assess the abilities of Large Language Models (LLMs) for spatial understanding and reasoning. Our evaluation of API-based and open-sourced LLMs shows that while some commercial LLMs exhibit strong reasoning abilities, open-sourced competitors can demonstrate almost the same level of quality; however, all models still have significant room for improvement. We identify typical reasons for LLM failures and discuss possible ways to deal with them. Datasets and evaluation code are released (https://github.com/altsoph/PLUGH).