 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Assistance Reduces Persistence and Hurts Independent Performance
Apr 07, 2026People often optimize for long-term goals in collaboration: A mentor or companion doesn't just answer questions, but also scaffolds learning, tracks progress, and prioritizes the other person's growth over immediate results. In contrast, current AI systems are fundamentally short-sighted collaborators - optimized for providing instant and complete responses, without ever saying no (unless for safety reasons). What are the consequences of this dynamic? Here, through a series of randomized controlled trials on human-AI interactions (N = 1,222), we provide causal evidence for two key consequences of AI assistance: reduced persistence and impairment of unassisted performance. Across a variety of tasks, including mathematical reasoning and reading comprehension, we find that although AI assistance improves performance in the short-term, people perform significantly worse without AI and are more likely to give up. Notably, these effects emerge after only brief interactions with AI (approximately 10 minutes). These findings are particularly concerning because persistence is foundational to skill acquisition and is one of the strongest predictors of long-term learning. We posit that persistence is reduced because AI conditions people to expect immediate answers, thereby denying them the experience of working through challenges on their own. These results suggest the need for AI model development to prioritize scaffolding long-term competence alongside immediate task completion.
Modularity benefits reinforcement learning agents with competing homeostatic drives
Apr 13, 2022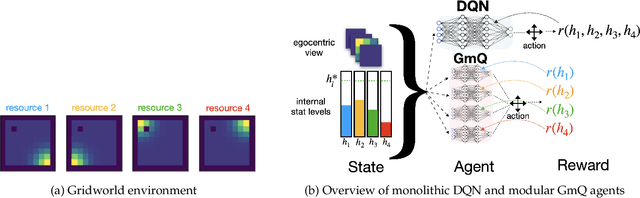
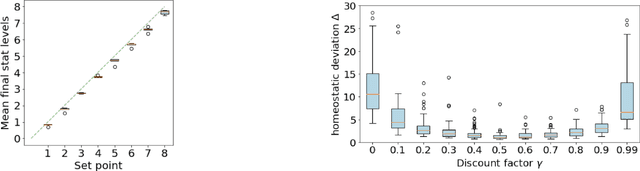
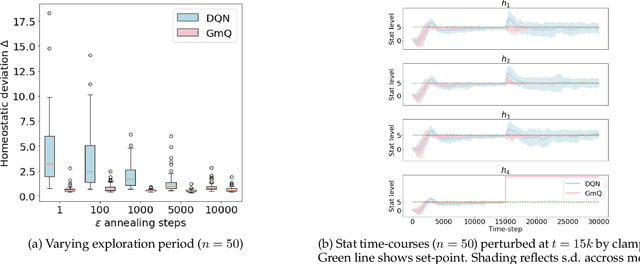
The problem of balancing conflicting needs is fundamental to intelligence. Standard reinforcement learning algorithms maximize a scalar reward, which requires combining different objective-specific rewards into a single number. Alternatively, different objectives could also be combined at the level of action value, such that specialist modules responsible for different objectives submit different action suggestions to a decision process, each based on rewards that are independent of one another. In this work, we explore the potential benefits of this alternative strategy. We investigate a biologically relevant multi-objective problem, the continual homeostasis of a set of variables, and compare a monolithic deep Q-network to a modular network with a dedicated Q-learner for each variable. We find that the modular agent: a) requires minimal exogenously determined exploration; b) has improved sample efficiency; and c) is more robust to out-of-domain perturbation.
Connecting Context-specific Adaptation in Humans to Meta-learning
Dec 01, 2020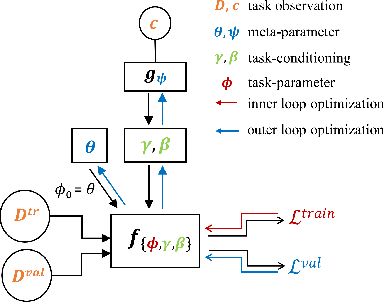
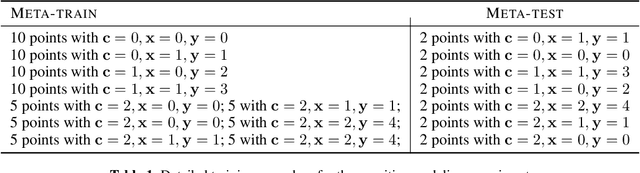


Cognitive control, the ability of a system to adapt to the demands of a task, is an integral part of cognition. A widely accepted fact about cognitive control is that it is context-sensitive: Adults and children alike infer information about a task's demands from contextual cues and use these inferences to learn from ambiguous cues. However, the precise way in which people use contextual cues to guide adaptation to a new task remains poorly understood. This work connects the context-sensitive nature of cognitive control to a method for meta-learning with context-conditioned adaptation. We begin by identifying an essential difference between human learning and current approaches to meta-learning: In contrast to humans, existing meta-learning algorithms do not make use of task-specific contextual cues but instead rely exclusively on online feedback in the form of task-specific labels or rewards. To remedy this, we introduce a framework for using contextual information about a task to guide the initialization of task-specific models before adaptation to online feedback. We show how context-conditioned meta-learning can capture human behavior in a cognitive task and how it can be scaled to improve the speed of learning in various settings, including few-shot classification and low-sample reinforcement learning. Our work demonstrates that guiding meta-learning with task information can capture complex, human-like behavior, thereby deepening our understanding of cognitive control.
Investigating Human Priors for Playing Video Games
Jul 25, 2018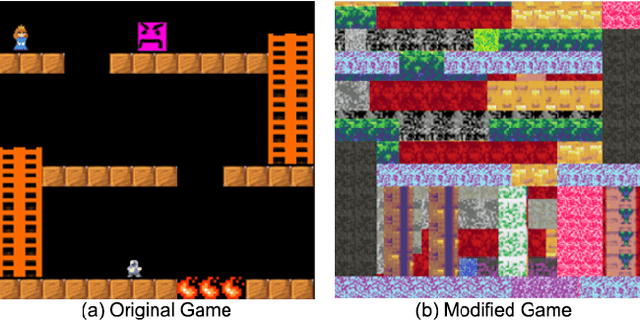

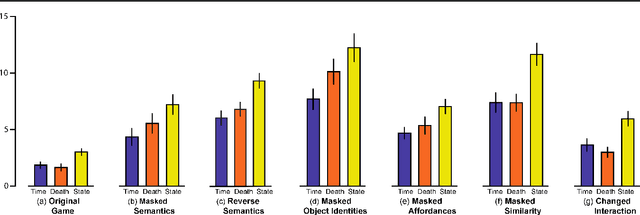
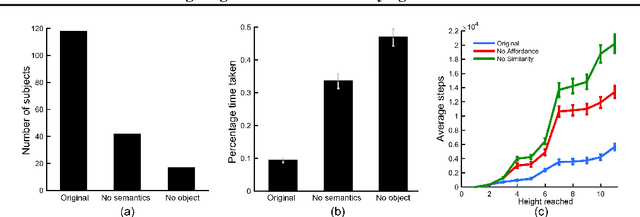
What makes humans so good at solving seemingly complex video games? Unlike computers, humans bring in a great deal of prior knowledge about the world, enabling efficient decision making. This paper investigates the role of human priors for solving video games. Given a sample game, we conduct a series of ablation studies to quantify the importance of various priors on human performance. We do this by modifying the video game environment to systematically mask different types of visual information that could be used by humans as priors. We find that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Furthermore, our results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play. Videos and the game manipulations are available at https://rach0012.github.io/humanRL_website/
* ICML 2018
A rational analysis of curiosity
May 11, 2017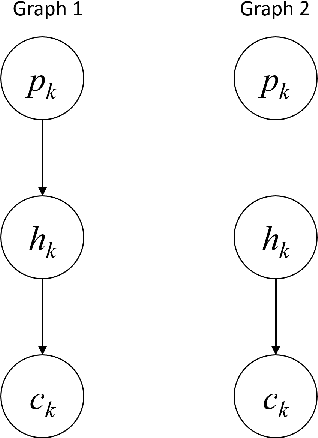
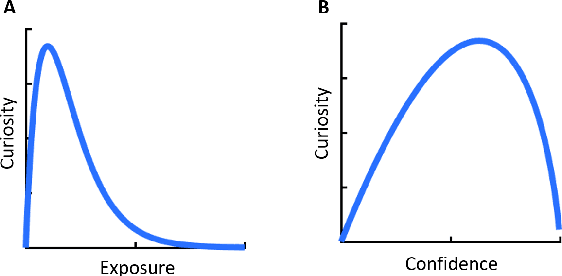
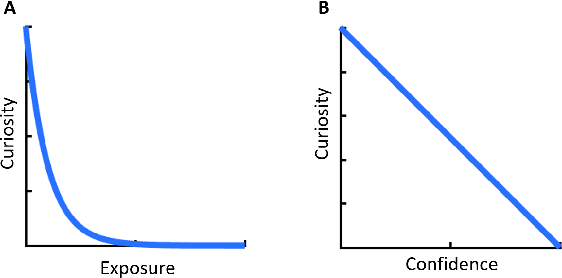
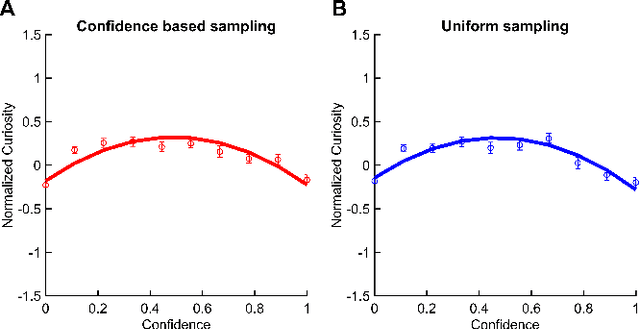
We present a rational analysis of curiosity, proposing that people's curiosity is driven by seeking stimuli that maximize their ability to make appropriate responses in the future. This perspective offers a way to unify previous theories of curiosity into a single framework. Experimental results confirm our model's predictions, showing how the relationship between curiosity and confidence can change significantly depending on the nature of the environment.