 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Abstractive Summarization of Bengali Text Documents
Feb 19, 2021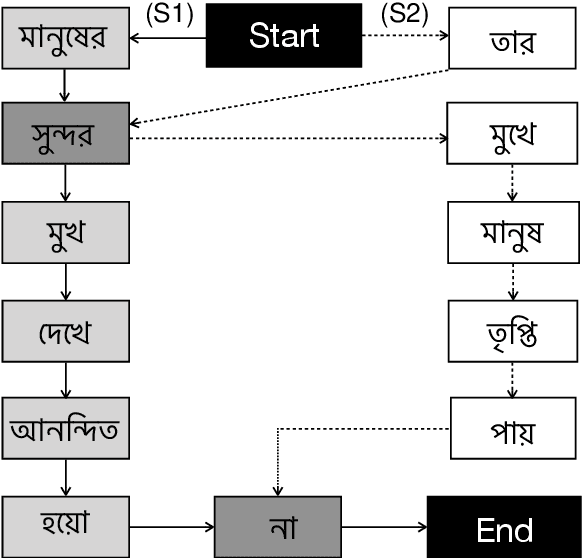
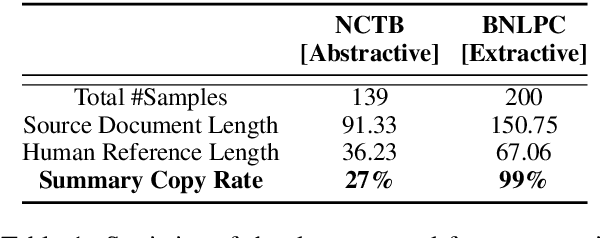

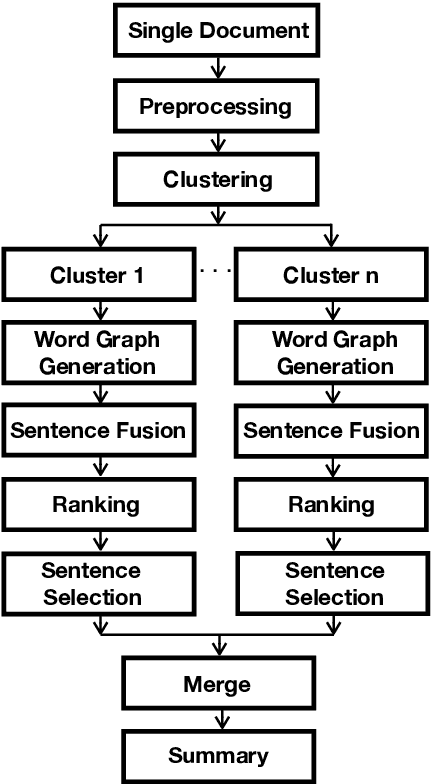
Abstractive summarization systems generally rely on large collections of document-summary pairs. However, the performance of abstractive systems remains a challenge due to the unavailability of parallel data for low-resource languages like Bengali. To overcome this problem, we propose a graph-based unsupervised abstractive summarization system in the single-document setting for Bengali text documents, which requires only a Part-Of-Speech (POS) tagger and a pre-trained language model trained on Bengali texts. We also provide a human-annotated dataset with document-summary pairs to evaluate our abstractive model and to support the comparison of future abstractive summarization systems of the Bengali Language. We conduct experiments on this dataset and compare our system with several well-established unsupervised extractive summarization systems. Our unsupervised abstractive summarization model outperforms the baselines without being exposed to any human-annotated reference summaries.