 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXL-HeadTags: Leveraging Multimodal Retrieval Augmentation for the Multilingual Generation of News Headlines and Tags
Jun 07, 2024



Millions of news articles published online daily can overwhelm readers. Headlines and entity (topic) tags are essential for guiding readers to decide if the content is worth their time. While headline generation has been extensively studied, tag generation remains largely unexplored, yet it offers readers better access to topics of interest. The need for conciseness in capturing readers' attention necessitates improved content selection strategies for identifying salient and relevant segments within lengthy articles, thereby guiding language models effectively. To address this, we propose to leverage auxiliary information such as images and captions embedded in the articles to retrieve relevant sentences and utilize instruction tuning with variations to generate both headlines and tags for news articles in a multilingual context. To make use of the auxiliary information, we have compiled a dataset named XL-HeadTags, which includes 20 languages across 6 diverse language families. Through extensive evaluation, we demonstrate the effectiveness of our plug-and-play multimodal-multilingual retrievers for both tasks. Additionally, we have developed a suite of tools for processing and evaluating multilingual texts, significantly contributing to the research community by enabling more accurate and efficient analysis across languages.
Crime Prediction using Machine Learning with a Novel Crime Dataset
Nov 03, 2022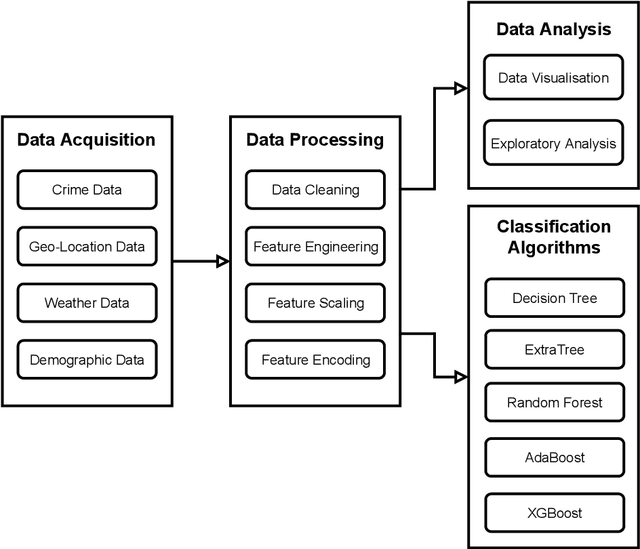

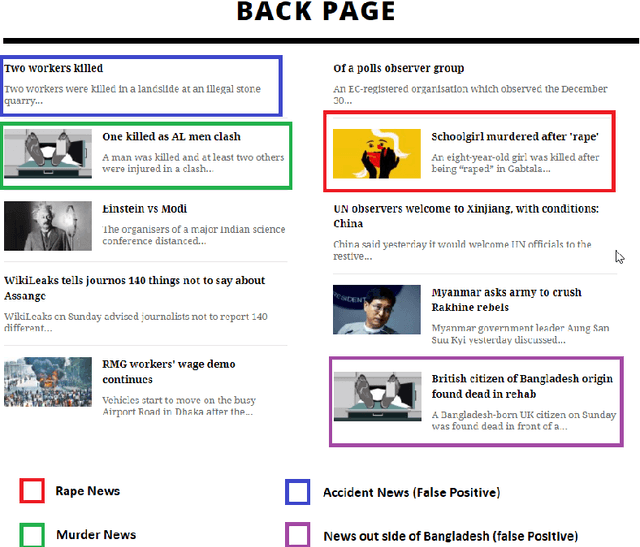
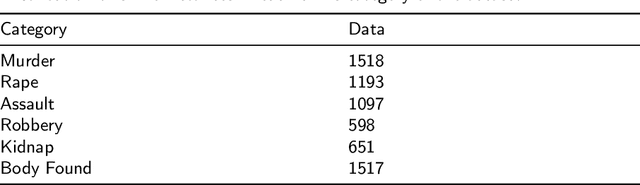
Crime is an unlawful act that carries legal repercussions. Bangladesh has a high crime rate due to poverty, population growth, and many other socio-economic issues. For law enforcement agencies, understanding crime patterns is essential for preventing future criminal activity. For this purpose, these agencies need structured crime database. This paper introduces a novel crime dataset that contains temporal, geographic, weather, and demographic data about 6574 crime incidents of Bangladesh. We manually gather crime news articles of a seven year time span from a daily newspaper archive. We extract basic features from these raw text. Using these basic features, we then consult standard service-providers of geo-location and weather data in order to garner these information related to the collected crime incidents. Furthermore, we collect demographic information from Bangladesh National Census data. All these information are combined that results in a standard machine learning dataset. Together, 36 features are engineered for the crime prediction task. Five supervised machine learning classification algorithms are then evaluated on this newly built dataset and satisfactory results are achieved. We also conduct exploratory analysis on various aspects the dataset. This dataset is expected to serve as the foundation for crime incidence prediction systems for Bangladesh and other countries. The findings of this study will help law enforcement agencies to forecast and contain crime as well as to ensure optimal resource allocation for crime patrol and prevention.