 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoverty rate prediction using multi-modal survey and earth observation data
Jul 21, 2023



This work presents an approach for combining household demographic and living standards survey questions with features derived from satellite imagery to predict the poverty rate of a region. Our approach utilizes visual features obtained from a single-step featurization method applied to freely available 10m/px Sentinel-2 surface reflectance satellite imagery. These visual features are combined with ten survey questions in a proxy means test (PMT) to estimate whether a household is below the poverty line. We show that the inclusion of visual features reduces the mean error in poverty rate estimates from 4.09% to 3.88% over a nationally representative out-of-sample test set. In addition to including satellite imagery features in proxy means tests, we propose an approach for selecting a subset of survey questions that are complementary to the visual features extracted from satellite imagery. Specifically, we design a survey variable selection approach guided by the full survey and image features and use the approach to determine the most relevant set of small survey questions to include in a PMT. We validate the choice of small survey questions in a downstream task of predicting the poverty rate using the small set of questions. This approach results in the best performance -- errors in poverty rate decrease from 4.09% to 3.71%. We show that extracted visual features encode geographic and urbanization differences between regions.
Rapid building damage assessment workflow: An implementation for the 2023 Rolling Fork, Mississippi tornado event
Jun 21, 2023


Rapid and accurate building damage assessments from high-resolution satellite imagery following a natural disaster is essential to inform and optimize first responder efforts. However, performing such building damage assessments in an automated manner is non-trivial due to the challenges posed by variations in disaster-specific damage, diversity in satellite imagery, and the dearth of extensive, labeled datasets. To circumvent these issues, this paper introduces a human-in-the-loop workflow for rapidly training building damage assessment models after a natural disaster. This article details a case study using this workflow, executed in partnership with the American Red Cross during a tornado event in Rolling Fork, Mississippi in March, 2023. The output from our human-in-the-loop modeling process achieved a precision of 0.86 and recall of 0.80 for damaged buildings when compared to ground truth data collected post-disaster. This workflow was implemented end-to-end in under 2 hours per satellite imagery scene, highlighting its potential for real-time deployment.
Dwelling Type Classification for Disaster Risk Assessment Using Satellite Imagery
Nov 16, 2022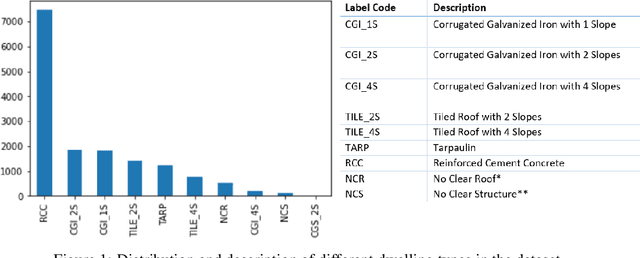
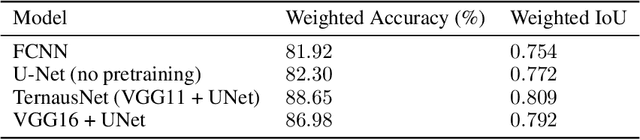

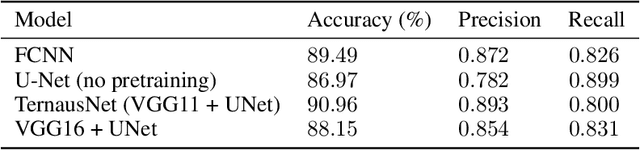
Vulnerability and risk assessment of neighborhoods is essential for effective disaster preparedness. Existing traditional systems, due to dependency on time-consuming and cost-intensive field surveying, do not provide a scalable way to decipher warnings and assess the precise extent of the risk at a hyper-local level. In this work, machine learning was used to automate the process of identifying dwellings and their type to build a potentially more effective disaster vulnerability assessment system. First, satellite imageries of low-income settlements and vulnerable areas in India were used to identify 7 different dwelling types. Specifically, we formulated the dwelling type classification as a semantic segmentation task and trained a U-net based neural network model, namely TernausNet, with the data we collected. Then a risk score assessment model was employed, using the determined dwelling type along with an inundation model of the regions. The entire pipeline was deployed to multiple locations prior to natural hazards in India in 2020. Post hoc ground-truth data from those regions was collected to validate the efficacy of this model which showed promising performance. This work can aid disaster response organizations and communities at risk by providing household-level risk information that can inform preemptive actions.
Fast building segmentation from satellite imagery and few local labels
Jun 10, 2022

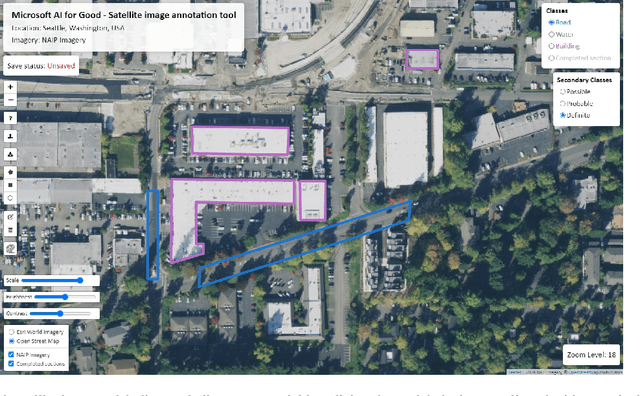

Innovations in computer vision algorithms for satellite image analysis can enable us to explore global challenges such as urbanization and land use change at the planetary level. However, domain shift problems are a common occurrence when trying to replicate models that drive these analyses to new areas, particularly in the developing world. If a model is trained with imagery and labels from one location, then it usually will not generalize well to new locations where the content of the imagery and data distributions are different. In this work, we consider the setting in which we have a single large satellite imagery scene over which we want to solve an applied problem -- building footprint segmentation. Here, we do not necessarily need to worry about creating a model that generalizes past the borders of our scene but can instead train a local model. We show that surprisingly few labels are needed to solve the building segmentation problem with very high-resolution (0.5m/px) satellite imagery with this setting in mind. Our best model trained with just 527 sparse polygon annotations (an equivalent of 1500 x 1500 densely labeled pixels) has a recall of 0.87 over held out footprints and a R2 of 0.93 on the task of counting the number of buildings in 200 x 200-meter windows. We apply our models over high-resolution imagery in Amman, Jordan in a case study on urban change detection.
A machine learning pipeline for aiding school identification from child trafficking images
Jun 09, 2021
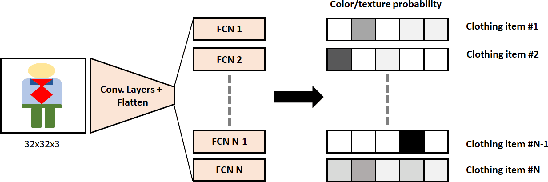
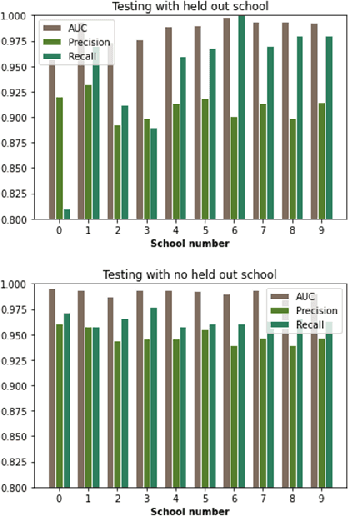
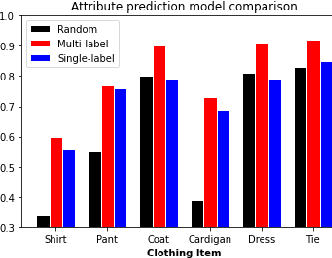
Child trafficking in a serious problem around the world. Every year there are more than 4 million victims of child trafficking around the world, many of them for the purposes of child sexual exploitation. In collaboration with UK Police and a non-profit focused on child abuse prevention, Global Emancipation Network, we developed a proof-of-concept machine learning pipeline to aid the identification of children from intercepted images. In this work, we focus on images that contain children wearing school uniforms to identify the school of origin. In the absence of a machine learning pipeline, this hugely time consuming and labor intensive task is manually conducted by law enforcement personnel. Thus, by automating aspects of the school identification process, we hope to significantly impact the speed of this portion of child identification. Our proposed pipeline consists of two machine learning models: i) to identify whether an image of a child contains a school uniform in it, and ii) identification of attributes of different school uniform items (such as color/texture of shirts, sweaters, blazers etc.). We describe the data collection, labeling, model development and validation process, along with strategies for efficient searching of schools using the model predictions.