 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACE: A Flexible Framework for Membership Privacy Estimation in Generative Models
Paper and Code
Sep 11, 2020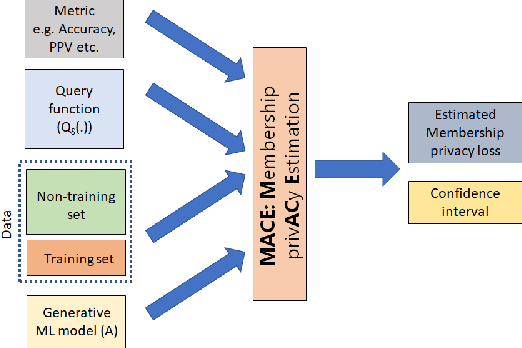
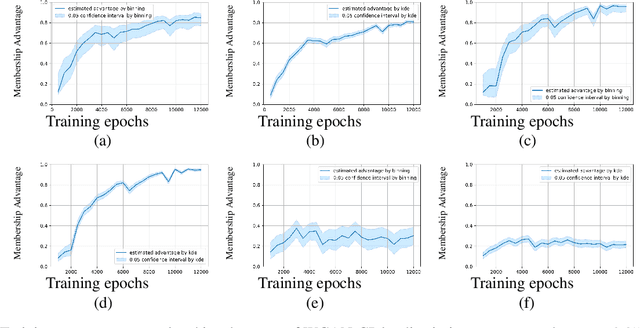
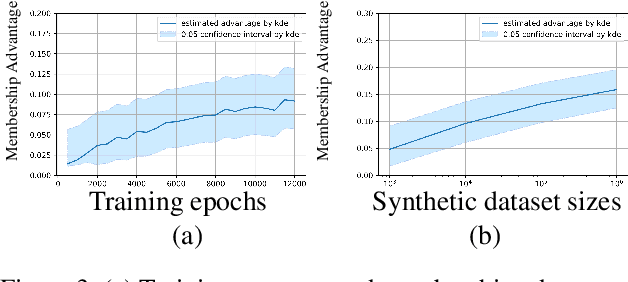
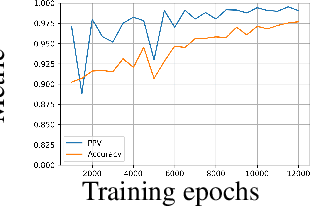
Generative models are widely used for publishing synthetic datasets. Despite practical successes, recent works have shown some generative models may leak privacy of the data that have been used during training. Membership inference attacks aim to determine whether a sample has been used in the training set given query access to the model API. Despite recent work in this area, many of the attacks designed against generative models require very specific attributes from the learned models (e.g. discriminator scores, generated images, etc.). Furthermore, many of these attacks are heuristic and do not provide effective bounds for privacy loss. In this work, we formally study the membership privacy leakage risk of generative models. Specifically, we formulate membership privacy as a statistical divergence between training samples and hold-out samples, and propose sample-based methods to estimate this divergence. Unlike previous works, our proposed metric and estimators make realistic and flexible assumptions. First, we use a generalizable metric as an alternative to accuracy, since practical model training often leads to imbalanced train/hold-out splits. Second, our estimators are capable of estimating statistical divergence using any scalar or vector valued attributes from the learned model instead of very specific attributes. Furthermore, we show a connection to differential privacy. This allows our proposed estimators to provide a data-driven certificate to understand the privacy budget needed for differentially private generative models. We demonstrate the utility of our framework through experimental demonstrations on different generative models using various model attributes yielding some new insights about membership leakage and vulnerabilities of models.