 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel ML-driven Test Case Selection Approach for Enhancing the Performance of Grammatical Evolution
Dec 21, 2023


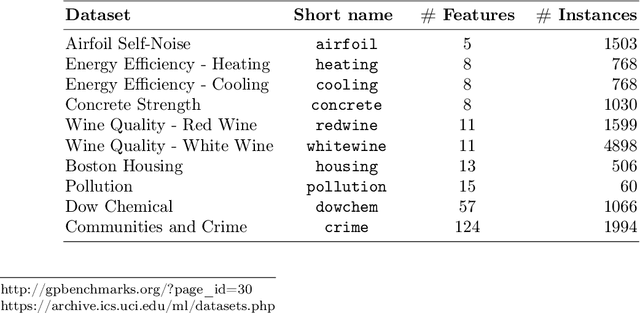
Computational cost in metaheuristics such as Evolutionary Algorithms (EAs) is often a major concern, particularly with their ability to scale. In data-based training, traditional EAs typically use a significant portion, if not all, of the dataset for model training and fitness evaluation in each generation. This makes EAs suffer from high computational costs incurred during the fitness evaluation of the population, particularly when working with large datasets. To mitigate this issue, we propose a Machine Learning (ML)-driven Distance-based Selection (DBS) algorithm that reduces the fitness evaluation time by optimizing test cases. We test our algorithm by applying it to 24 benchmark problems from Symbolic Regression (SR) and digital circuit domains and then using Grammatical Evolution (GE) to train models using the reduced dataset. We use GE to test DBS on SR and produce a system flexible enough to test it on digital circuit problems further. The quality of the solutions is tested and compared against the conventional training method to measure the coverage of training data selected using DBS, i.e., how well the subset matches the statistical properties of the entire dataset. Moreover, the effect of optimized training data on run time and the effective size of the evolved solutions is analyzed. Experimental and statistical evaluations of the results show our method empowered GE to yield superior or comparable solutions to the baseline (using the full datasets) with smaller sizes and demonstrates computational efficiency in terms of speed.
Assessment of Differentially Private Synthetic Data for Utility and Fairness in End-to-End Machine Learning Pipelines for Tabular Data
Oct 30, 2023



Differentially private (DP) synthetic data sets are a solution for sharing data while preserving the privacy of individual data providers. Understanding the effects of utilizing DP synthetic data in end-to-end machine learning pipelines impacts areas such as health care and humanitarian action, where data is scarce and regulated by restrictive privacy laws. In this work, we investigate the extent to which synthetic data can replace real, tabular data in machine learning pipelines and identify the most effective synthetic data generation techniques for training and evaluating machine learning models. We investigate the impacts of differentially private synthetic data on downstream classification tasks from the point of view of utility as well as fairness. Our analysis is comprehensive and includes representatives of the two main types of synthetic data generation algorithms: marginal-based and GAN-based. To the best of our knowledge, our work is the first that: (i) proposes a training and evaluation framework that does not assume that real data is available for testing the utility and fairness of machine learning models trained on synthetic data; (ii) presents the most extensive analysis of synthetic data set generation algorithms in terms of utility and fairness when used for training machine learning models; and (iii) encompasses several different definitions of fairness. Our findings demonstrate that marginal-based synthetic data generators surpass GAN-based ones regarding model training utility for tabular data. Indeed, we show that models trained using data generated by marginal-based algorithms can exhibit similar utility to models trained using real data. Our analysis also reveals that the marginal-based synthetic data generator MWEM PGM can train models that simultaneously achieve utility and fairness characteristics close to those obtained by models trained with real data.
An Analysis of the Deployment of Models Trained on Private Tabular Synthetic Data: Unexpected Surprises
Jun 15, 2021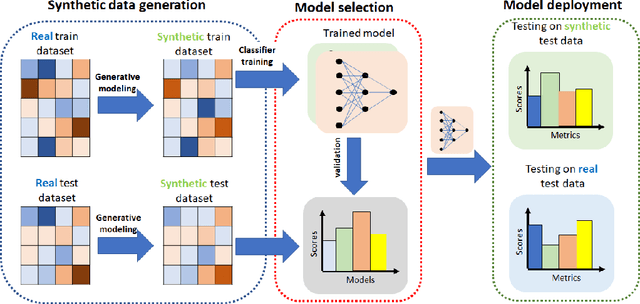
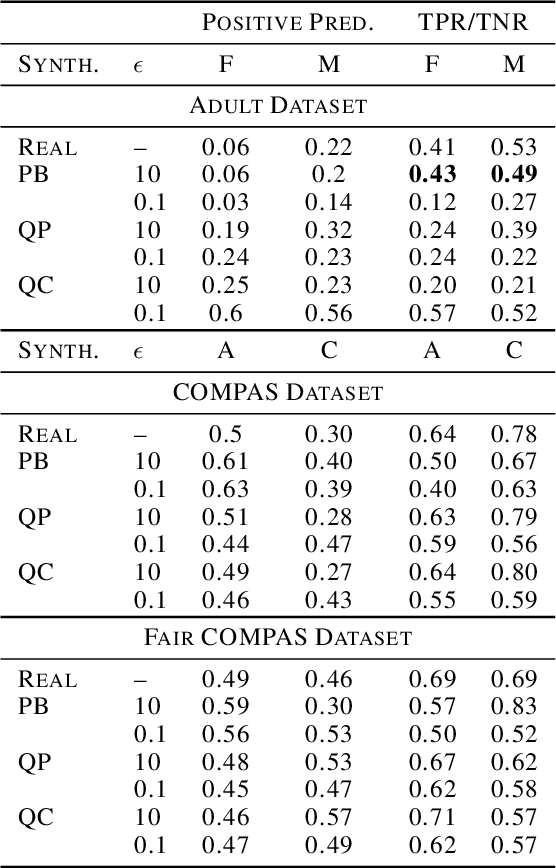
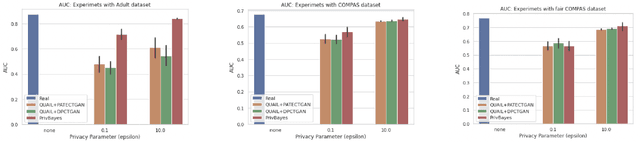
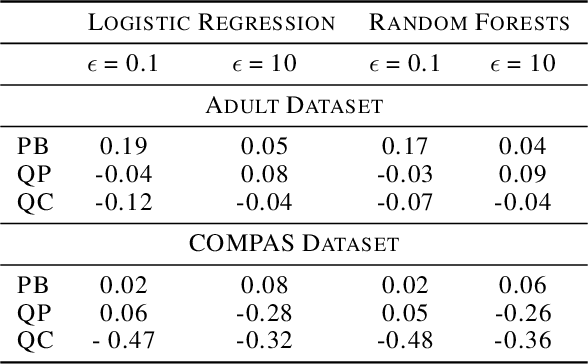
Diferentially private (DP) synthetic datasets are a powerful approach for training machine learning models while respecting the privacy of individual data providers. The effect of DP on the fairness of the resulting trained models is not yet well understood. In this contribution, we systematically study the effects of differentially private synthetic data generation on classification. We analyze disparities in model utility and bias caused by the synthetic dataset, measured through algorithmic fairness metrics. Our first set of results show that although there seems to be a clear negative correlation between privacy and utility (the more private, the less accurate) across all data synthesizers we evaluated, more privacy does not necessarily imply more bias. Additionally, we assess the effects of utilizing synthetic datasets for model training and model evaluation. We show that results obtained on synthetic data can misestimate the actual model performance when it is deployed on real data. We hence advocate on the need for defining proper testing protocols in scenarios where differentially private synthetic datasets are utilized for model training and evaluation.
Learning task structure via sparsity grouped multitask learning
Sep 15, 2017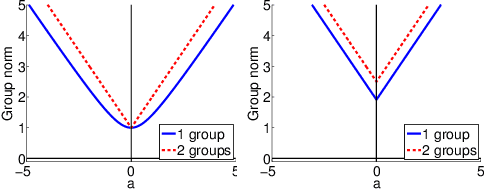

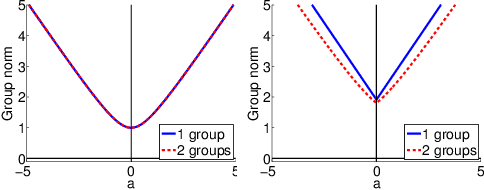
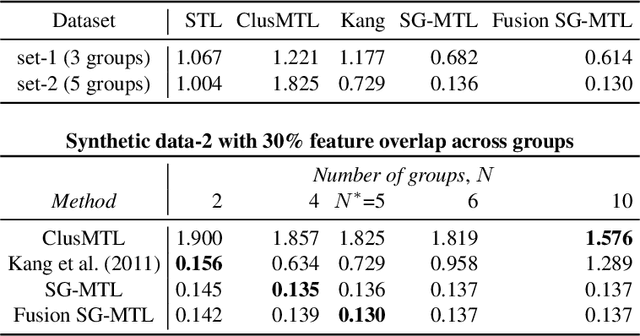
Sparse mapping has been a key methodology in many high-dimensional scientific problems. When multiple tasks share the set of relevant features, learning them jointly in a group drastically improves the quality of relevant feature selection. However, in practice this technique is used limitedly since such grouping information is usually hidden. In this paper, our goal is to recover the group structure on the sparsity patterns and leverage that information in the sparse learning. Toward this, we formulate a joint optimization problem in the task parameter and the group membership, by constructing an appropriate regularizer to encourage sparse learning as well as correct recovery of task groups. We further demonstrate that our proposed method recovers groups and the sparsity patterns in the task parameters accurately by extensive experiments.