 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Solutions for Breast Cancer Diagnosis with Grammatical Evolution and Data Augmentation
Jan 25, 2024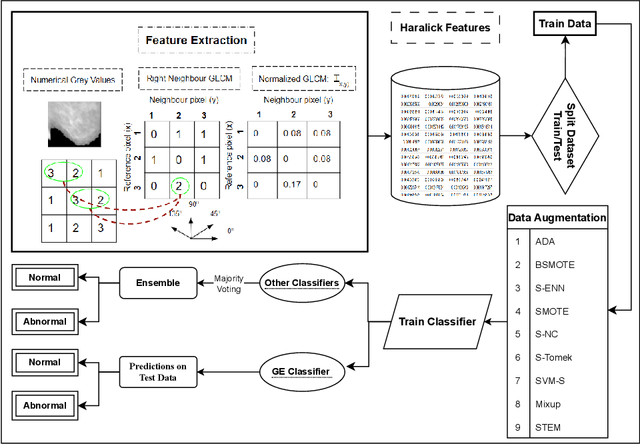



Medical imaging diagnosis increasingly relies on Machine Learning (ML) models. This is a task that is often hampered by severely imbalanced datasets, where positive cases can be quite rare. Their use is further compromised by their limited interpretability, which is becoming increasingly important. While post-hoc interpretability techniques such as SHAP and LIME have been used with some success on so-called black box models, the use of inherently understandable models makes such endeavors more fruitful. This paper addresses these issues by demonstrating how a relatively new synthetic data generation technique, STEM, can be used to produce data to train models produced by Grammatical Evolution (GE) that are inherently understandable. STEM is a recently introduced combination of the Synthetic Minority Oversampling Technique (SMOTE), Edited Nearest Neighbour (ENN), and Mixup; it has previously been successfully used to tackle both between class and within class imbalance issues. We test our technique on the Digital Database for Screening Mammography (DDSM) and the Wisconsin Breast Cancer (WBC) datasets and compare Area Under the Curve (AUC) results with an ensemble of the top three performing classifiers from a set of eight standard ML classifiers with varying degrees of interpretability. We demonstrate that the GE-derived models present the best AUC while still maintaining interpretable solutions.
A Novel ML-driven Test Case Selection Approach for Enhancing the Performance of Grammatical Evolution
Dec 21, 2023


Computational cost in metaheuristics such as Evolutionary Algorithms (EAs) is often a major concern, particularly with their ability to scale. In data-based training, traditional EAs typically use a significant portion, if not all, of the dataset for model training and fitness evaluation in each generation. This makes EAs suffer from high computational costs incurred during the fitness evaluation of the population, particularly when working with large datasets. To mitigate this issue, we propose a Machine Learning (ML)-driven Distance-based Selection (DBS) algorithm that reduces the fitness evaluation time by optimizing test cases. We test our algorithm by applying it to 24 benchmark problems from Symbolic Regression (SR) and digital circuit domains and then using Grammatical Evolution (GE) to train models using the reduced dataset. We use GE to test DBS on SR and produce a system flexible enough to test it on digital circuit problems further. The quality of the solutions is tested and compared against the conventional training method to measure the coverage of training data selected using DBS, i.e., how well the subset matches the statistical properties of the entire dataset. Moreover, the effect of optimized training data on run time and the effective size of the evolved solutions is analyzed. Experimental and statistical evaluations of the results show our method empowered GE to yield superior or comparable solutions to the baseline (using the full datasets) with smaller sizes and demonstrates computational efficiency in terms of speed.
STEM Rebalance: A Novel Approach for Tackling Imbalanced Datasets using SMOTE, Edited Nearest Neighbour, and Mixup
Nov 13, 2023Imbalanced datasets in medical imaging are characterized by skewed class proportions and scarcity of abnormal cases. When trained using such data, models tend to assign higher probabilities to normal cases, leading to biased performance. Common oversampling techniques such as SMOTE rely on local information and can introduce marginalization issues. This paper investigates the potential of using Mixup augmentation that combines two training examples along with their corresponding labels to generate new data points as a generic vicinal distribution. To this end, we propose STEM, which combines SMOTE-ENN and Mixup at the instance level. This integration enables us to effectively leverage the entire distribution of minority classes, thereby mitigating both between-class and within-class imbalances. We focus on the breast cancer problem, where imbalanced datasets are prevalent. The results demonstrate the effectiveness of STEM, which achieves AUC values of 0.96 and 0.99 in the Digital Database for Screening Mammography and Wisconsin Breast Cancer (Diagnostics) datasets, respectively. Moreover, this method shows promising potential when applied with an ensemble of machine learning (ML) classifiers.
* 7 pages, 4 figures, International Conference on Intelligent Computer Communication and Processing