 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA machine learning approach for image classification in synthetic aperture RADAR
Aug 06, 2025



We consider the problem in Synthetic Aperture RADAR (SAR) of identifying and classifying objects located on the ground by means of Convolutional Neural Networks (CNNs). Specifically, we adopt a single scattering approximation to classify the shape of the object using both simulated SAR data and reconstructed images from this data, and we compare the success of these approaches. We then identify ice types in real SAR imagery from the satellite Sentinel-1. In both experiments we achieve a promising high classification accuracy ($\geq$75\%). Our results demonstrate the effectiveness of CNNs in using SAR data for both geometric and environmental classification tasks. Our investigation also explores the effect of SAR data acquisition at different antenna heights on our ability to classify objects successfully.
Defending Against Frequency-Based Attacks with Diffusion Models
Apr 15, 2025Adversarial training is a common strategy for enhancing model robustness against adversarial attacks. However, it is typically tailored to the specific attack types it is trained on, limiting its ability to generalize to unseen threat models. Adversarial purification offers an alternative by leveraging a generative model to remove perturbations before classification. Since the purifier is trained independently of both the classifier and the threat models, it is better equipped to handle previously unseen attack scenarios. Diffusion models have proven highly effective for noise purification, not only in countering pixel-wise adversarial perturbations but also in addressing non-adversarial data shifts. In this study, we broaden the focus beyond pixel-wise robustness to explore the extent to which purification can mitigate both spectral and spatial adversarial attacks. Our findings highlight its effectiveness in handling diverse distortion patterns across low- to high-frequency regions.
Narrowing Class-Wise Robustness Gaps in Adversarial Training
Mar 20, 2025Efforts to address declining accuracy as a result of data shifts often involve various data-augmentation strategies. Adversarial training is one such method, designed to improve robustness to worst-case distribution shifts caused by adversarial examples. While this method can improve robustness, it may also hinder generalization to clean examples and exacerbate performance imbalances across different classes. This paper explores the impact of adversarial training on both overall and class-specific performance, as well as its spill-over effects. We observe that enhanced labeling during training boosts adversarial robustness by 53.50% and mitigates class imbalances by 5.73%, leading to improved accuracy in both clean and adversarial settings compared to standard adversarial training.
Electrical Impedance Tomography for Anisotropic Media: a Machine Learning Approach to Classify Inclusions
Feb 06, 2025



We consider the problem in Electrical Impedance Tomography (EIT) of identifying one or multiple inclusions in a background-conducting body $\Omega\subset\mathbb{R}^2$, from the knowledge of a finite number of electrostatic measurements taken on its boundary $\partial\Omega$ and modelled by the Dirichlet-to-Neumann (D-N) matrix. Once the presence of one inclusion in $\Omega$ is established, our model, combined with the machine learning techniques of Artificial Neural Networks (ANN) and Support Vector Machines (SVM), may be used to determine the size of the inclusion, the presence of multiple inclusions, and also that of anisotropy within the inclusion(s). Utilising both real and simulated datasets within a 16-electrode setup, we achieve a high rate of inclusion detection and show that two measurements are sufficient to achieve a good level of accuracy when predicting the size of an inclusion. This underscores the substantial potential of integrating machine learning approaches with the more classical analysis of EIT and the inverse inclusion problem to extract critical insights, such as the presence of anisotropy.
Label Augmentation for Neural Networks Robustness
Aug 04, 2024



Out-of-distribution generalization can be categorized into two types: common perturbations arising from natural variations in the real world and adversarial perturbations that are intentionally crafted to deceive neural networks. While deep neural networks excel in accuracy under the assumption of identical distributions between training and test data, they often encounter out-of-distribution scenarios resulting in a significant decline in accuracy. Data augmentation methods can effectively enhance robustness against common corruptions, but they typically fall short in improving robustness against adversarial perturbations. In this study, we develop Label Augmentation (LA), which enhances robustness against both common and intentional perturbations and improves uncertainty estimation. Our findings indicate a Clean error rate improvement of up to 23.29% when employing LA in comparisons to the baseline. Additionally, it enhances robustness under common corruptions benchmark by up to 24.23%. When tested against FGSM and PGD attacks, improvements in adversarial robustness are noticeable, with enhancements of up to 53.18% for FGSM and 24.46% for PGD attacks.
Interpretable Solutions for Breast Cancer Diagnosis with Grammatical Evolution and Data Augmentation
Jan 25, 2024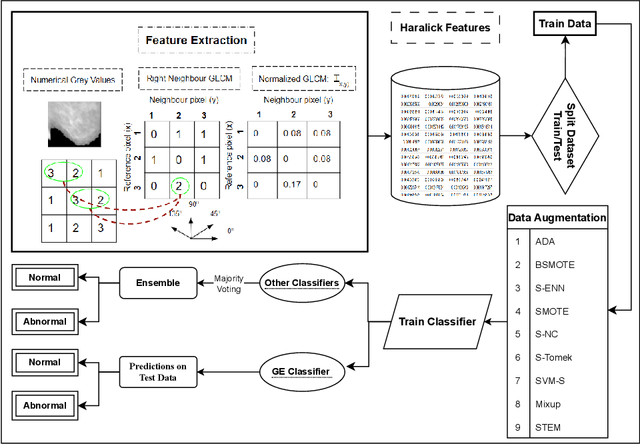



Medical imaging diagnosis increasingly relies on Machine Learning (ML) models. This is a task that is often hampered by severely imbalanced datasets, where positive cases can be quite rare. Their use is further compromised by their limited interpretability, which is becoming increasingly important. While post-hoc interpretability techniques such as SHAP and LIME have been used with some success on so-called black box models, the use of inherently understandable models makes such endeavors more fruitful. This paper addresses these issues by demonstrating how a relatively new synthetic data generation technique, STEM, can be used to produce data to train models produced by Grammatical Evolution (GE) that are inherently understandable. STEM is a recently introduced combination of the Synthetic Minority Oversampling Technique (SMOTE), Edited Nearest Neighbour (ENN), and Mixup; it has previously been successfully used to tackle both between class and within class imbalance issues. We test our technique on the Digital Database for Screening Mammography (DDSM) and the Wisconsin Breast Cancer (WBC) datasets and compare Area Under the Curve (AUC) results with an ensemble of the top three performing classifiers from a set of eight standard ML classifiers with varying degrees of interpretability. We demonstrate that the GE-derived models present the best AUC while still maintaining interpretable solutions.
STEM Rebalance: A Novel Approach for Tackling Imbalanced Datasets using SMOTE, Edited Nearest Neighbour, and Mixup
Nov 13, 2023Imbalanced datasets in medical imaging are characterized by skewed class proportions and scarcity of abnormal cases. When trained using such data, models tend to assign higher probabilities to normal cases, leading to biased performance. Common oversampling techniques such as SMOTE rely on local information and can introduce marginalization issues. This paper investigates the potential of using Mixup augmentation that combines two training examples along with their corresponding labels to generate new data points as a generic vicinal distribution. To this end, we propose STEM, which combines SMOTE-ENN and Mixup at the instance level. This integration enables us to effectively leverage the entire distribution of minority classes, thereby mitigating both between-class and within-class imbalances. We focus on the breast cancer problem, where imbalanced datasets are prevalent. The results demonstrate the effectiveness of STEM, which achieves AUC values of 0.96 and 0.99 in the Digital Database for Screening Mammography and Wisconsin Breast Cancer (Diagnostics) datasets, respectively. Moreover, this method shows promising potential when applied with an ensemble of machine learning (ML) classifiers.
* 7 pages, 4 figures, International Conference on Intelligent Computer Communication and Processing