 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Solutions for Breast Cancer Diagnosis with Grammatical Evolution and Data Augmentation
Jan 25, 2024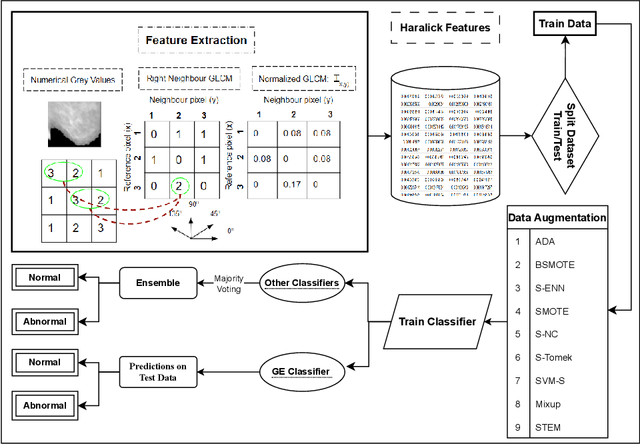



Medical imaging diagnosis increasingly relies on Machine Learning (ML) models. This is a task that is often hampered by severely imbalanced datasets, where positive cases can be quite rare. Their use is further compromised by their limited interpretability, which is becoming increasingly important. While post-hoc interpretability techniques such as SHAP and LIME have been used with some success on so-called black box models, the use of inherently understandable models makes such endeavors more fruitful. This paper addresses these issues by demonstrating how a relatively new synthetic data generation technique, STEM, can be used to produce data to train models produced by Grammatical Evolution (GE) that are inherently understandable. STEM is a recently introduced combination of the Synthetic Minority Oversampling Technique (SMOTE), Edited Nearest Neighbour (ENN), and Mixup; it has previously been successfully used to tackle both between class and within class imbalance issues. We test our technique on the Digital Database for Screening Mammography (DDSM) and the Wisconsin Breast Cancer (WBC) datasets and compare Area Under the Curve (AUC) results with an ensemble of the top three performing classifiers from a set of eight standard ML classifiers with varying degrees of interpretability. We demonstrate that the GE-derived models present the best AUC while still maintaining interpretable solutions.