 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel ML-driven Test Case Selection Approach for Enhancing the Performance of Grammatical Evolution
Paper and Code



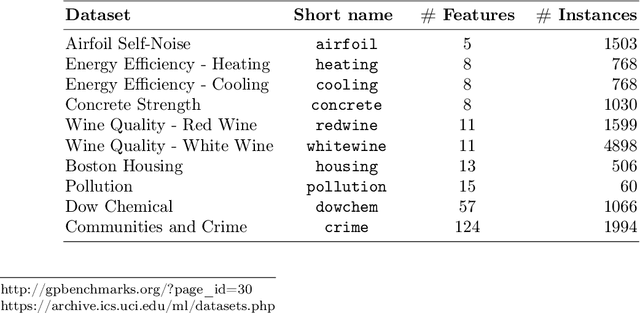
Computational cost in metaheuristics such as Evolutionary Algorithms (EAs) is often a major concern, particularly with their ability to scale. In data-based training, traditional EAs typically use a significant portion, if not all, of the dataset for model training and fitness evaluation in each generation. This makes EAs suffer from high computational costs incurred during the fitness evaluation of the population, particularly when working with large datasets. To mitigate this issue, we propose a Machine Learning (ML)-driven Distance-based Selection (DBS) algorithm that reduces the fitness evaluation time by optimizing test cases. We test our algorithm by applying it to 24 benchmark problems from Symbolic Regression (SR) and digital circuit domains and then using Grammatical Evolution (GE) to train models using the reduced dataset. We use GE to test DBS on SR and produce a system flexible enough to test it on digital circuit problems further. The quality of the solutions is tested and compared against the conventional training method to measure the coverage of training data selected using DBS, i.e., how well the subset matches the statistical properties of the entire dataset. Moreover, the effect of optimized training data on run time and the effective size of the evolved solutions is analyzed. Experimental and statistical evaluations of the results show our method empowered GE to yield superior or comparable solutions to the baseline (using the full datasets) with smaller sizes and demonstrates computational efficiency in terms of speed.