 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to End Collaborative Synthetic Data Generation
Dec 04, 2024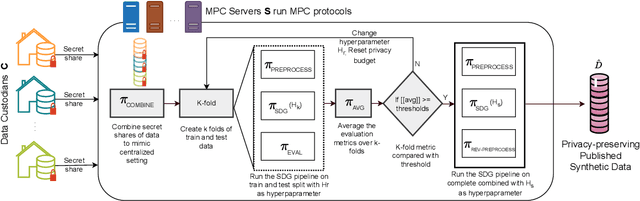


The success of AI is based on the availability of data to train models. While in some cases a single data custodian may have sufficient data to enable AI, often multiple custodians need to collaborate to reach a cumulative size required for meaningful AI research. The latter is, for example, often the case for rare diseases, with each clinical site having data for only a small number of patients. Recent algorithms for federated synthetic data generation are an important step towards collaborative, privacy-preserving data sharing. Existing techniques, however, focus exclusively on synthesizer training, assuming that the training data is already preprocessed and that the desired synthetic data can be delivered in one shot, without any hyperparameter tuning. In this paper, we propose an end-to-end collaborative framework for publishing of synthetic data that accounts for privacy-preserving preprocessing as well as evaluation. We instantiate this framework with Secure Multiparty Computation (MPC) protocols and evaluate it in a use case for privacy-preserving publishing of synthetic genomic data for leukemia.