 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Examples From CLI Usage: Can Transformers Help?
Paper and Code
Apr 27, 2022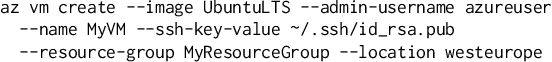
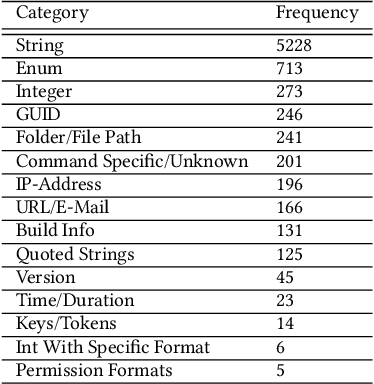
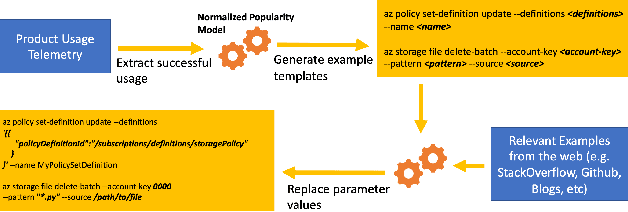
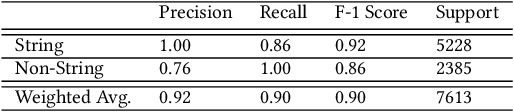
Continuous evolution in modern software often causes documentation, tutorials, and examples to be out of sync with changing interfaces and frameworks. Relying on outdated documentation and examples can lead programs to fail or be less efficient or even less secure. In response, programmers need to regularly turn to other resources on the web such as StackOverflow for examples to guide them in writing software. We recognize that this inconvenient, error-prone, and expensive process can be improved by using machine learning applied to software usage data. In this paper, we present our practical system which uses machine learning on large-scale telemetry data and documentation corpora, generating appropriate and complex examples that can be used to improve documentation. We discuss both feature-based and transformer-based machine learning approaches and demonstrate that our system achieves 100% coverage for the used functionalities in the product, providing up-to-date examples upon every release and reduces the numbers of PRs submitted by software owners writing and editing documentation by >68%. We also share valuable lessons learnt during the 3 years that our production quality system has been deployed for Azure Cloud Command Line Interface (Azure CLI).