 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
Feb 09, 2021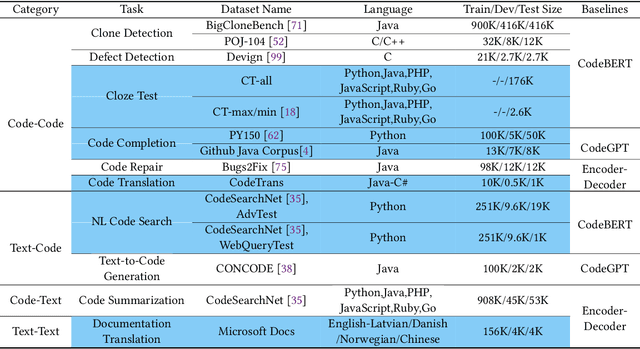


Benchmark datasets have a significant impact on accelerating research in programming language tasks. In this paper, we introduce CodeXGLUE, a benchmark dataset to foster machine learning research for program understanding and generation. CodeXGLUE includes a collection of 10 tasks across 14 datasets and a platform for model evaluation and comparison. CodeXGLUE also features three baseline systems, including the BERT-style, GPT-style, and Encoder-Decoder models, to make it easy for researchers to use the platform. The availability of such data and baselines can help the development and validation of new methods that can be applied to various program understanding and generation problems.
GraphCodeBERT: Pre-training Code Representations with Data Flow
Sep 29, 2020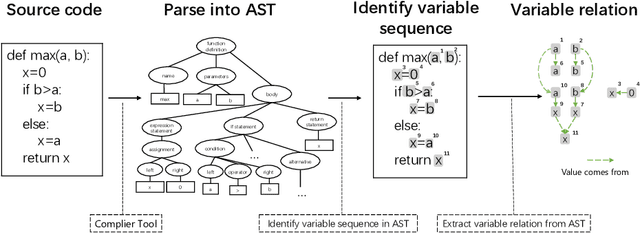
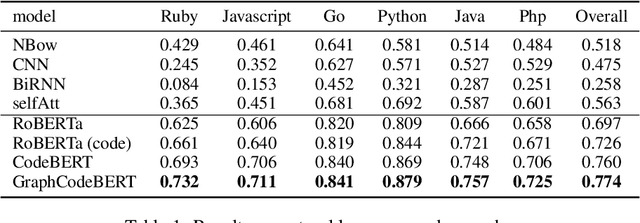
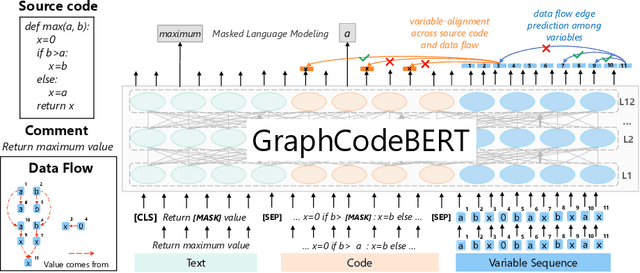
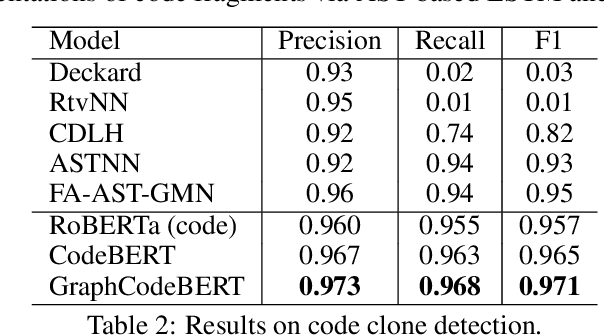
Pre-trained models for programming language have achieved dramatic empirical improvements on a variety of code-related tasks such as code search, code completion, code summarization, etc. However, existing pre-trained models regard a code snippet as a sequence of tokens, while ignoring the inherent structure of code, which provides crucial code semantics and would enhance the code understanding process. We present GraphCodeBERT, a pre-trained model for programming language that considers the inherent structure of code. Instead of taking syntactic-level structure of code like abstract syntax tree (AST), we use data flow in the pre-training stage, which is a semantic-level structure of code that encodes the relation of "where-the-value-comes-from" between variables. Such a semantic-level structure is neat and does not bring an unnecessarily deep hierarchy of AST, the property of which makes the model more efficient. We develop GraphCodeBERT based on Transformer. In addition to using the task of masked language modeling, we introduce two structure-aware pre-training tasks. One is to predict code structure edges, and the other is to align representations between source code and code structure. We implement the model in an efficient way with a graph-guided masked attention function to incorporate the code structure. We evaluate our model on four tasks, including code search, clone detection, code translation, and code refinement. Results show that code structure and newly introduced pre-training tasks can improve GraphCodeBERT and achieves state-of-the-art performance on the four downstream tasks. We further show that the model prefers structure-level attentions over token-level attentions in the task of code search.
Unit Test Case Generation with Transformers
Sep 11, 2020


Automated Unit Test Case generation has been the focus of extensive literature within the research community. Existing approaches are usually guided by the test coverage criteria, generating synthetic test cases that are often difficult to read or understand for developers. In this paper we propose AthenaTest, an approach that aims at generating unit test cases by learning from real-world, developer-written test cases. Our approach relies on a state-of-the-art sequence-to-sequence transformer model which is able to write useful test cases for a given method under test (i.e., focal method). We also introduce methods2test - the largest publicly available supervised parallel corpus of unit test case methods and corresponding focal methods in Java, which comprises 630k test cases mined from 70k open-source repositories hosted on GitHub. We use this dataset to train a transformer model to translate focal methods into the corresponding test cases. We evaluate the ability of our model in generating test cases using natural language processing as well as code-specific criteria. First, we assess the quality of the translation compared to the target test case, then we analyze properties of the test case such as syntactic correctness and number and variety of testing APIs (e.g., asserts). We execute the test cases, collect test coverage information, and compare them with test cases generated by EvoSuite and GPT-3. Finally, we survey professional developers on their preference in terms of readability, understandability, and testing effectiveness of the generated test cases.
IntelliCode Compose: Code Generation Using Transformer
May 16, 2020



In software development through integrated development environments (IDEs), code completion is one of the most widely used features. Nevertheless, majority of integrated development environments only support completion of methods and APIs, or arguments. In this paper, we introduce IntelliCode Compose $-$ a general-purpose multilingual code completion tool which is capable of predicting sequences of code tokens of arbitrary types, generating up to entire lines of syntactically correct code. It leverages state-of-the-art generative transformer model trained on 1.2 billion lines of source code in Python, $C\#$, JavaScript and TypeScript programming languages. IntelliCode Compose is deployed as a cloud-based web service. It makes use of client-side tree-based caching, efficient parallel implementation of the beam search decoder, and compute graph optimizations to meet edit-time completion suggestion requirements in the Visual Studio Code IDE and Azure Notebook. Our best model yields an average edit similarity of $86.7\%$ and a perplexity of 1.82 for Python programming language.