 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Efficacy Trade Off: Robustness against Data-Poisoning
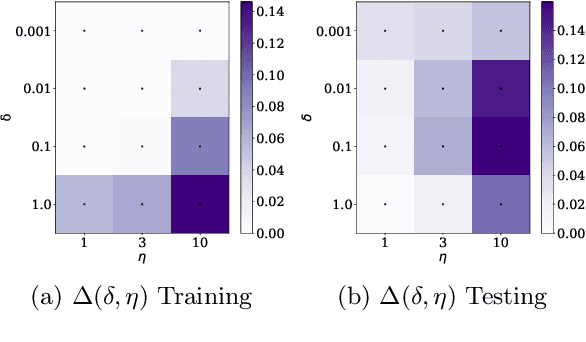
Jan 31, 2026Backdoor and data poisoning attacks can achieve high attack success while evading existing spectral and optimisation based defences. We show that this behaviour is not incidental, but arises from a fundamental geometric mechanism in input space. Using kernel ridge regression as an exact model of wide neural networks, we prove that clustered dirty label poisons induce a rank one spike in the input Hessian whose magnitude scales quadratically with attack efficacy. Crucially, for nonlinear kernels we identify a near clone regime in which poison efficacy remains order one while the induced input curvature vanishes, making the attack provably spectrally undetectable. We further show that input gradient regularisation contracts poison aligned Fisher and Hessian eigenmodes under gradient flow, yielding an explicit and unavoidable safety efficacy trade off by reducing data fitting capacity. For exponential kernels, this defence admits a precise interpretation as an anisotropic high pass filter that increases the effective length scale and suppresses near clone poisons. Extensive experiments on linear models and deep convolutional networks across MNIST and CIFAR 10 and CIFAR 100 validate the theory, demonstrating consistent lags between attack success and spectral visibility, and showing that regularisation and data augmentation jointly suppress poisoning. Our results establish when backdoors are inherently invisible, and provide the first end to end characterisation of poisoning, detectability, and defence through input space curvature.
Hessian Spectral Analysis at Foundation Model Scale
Jan 31, 2026Accurate Hessian spectra of foundation models have remained out of reach, leading most prior work to rely on small models or strong structural approximations. We show that faithful spectral analysis of the true Hessian is tractable at frontier scale. Using shard-local finite-difference Hessian vector products compatible with Fully Sharded Data Parallelism, we perform stochastic Lanczos quadrature on open-source language models with up to 100B parameters, producing the first large-scale spectral density estimates beyond the sub-10B regime. We characterize the numerical behavior of this pipeline, including finite-difference bias, floating-point noise amplification, and their effect on Krylov stability in fp32 and bf16, and derive practical operating regimes that are validated empirically. We further provide end-to-end runtime and memory scaling laws, showing that full-operator spectral probing incurs only a modest constant-factor overhead over first-order training. Crucially, direct access to the Hessian reveals that widely used block-diagonal curvature approximations can fail catastrophically, exhibiting order-one relative error and poor directional alignment even in mid-scale LLMs. Together, our results demonstrate that foundation-model Hessian spectra are both computable and qualitatively misrepresented by prevailing approximations, opening the door to principled curvature-based analysis at scale.
A Linear Approach to Data Poisoning
May 21, 2025We investigate the theoretical foundations of data poisoning attacks in machine learning models. Our analysis reveals that the Hessian with respect to the input serves as a diagnostic tool for detecting poisoning, exhibiting spectral signatures that characterize compromised datasets. We use random matrix theory (RMT) to develop a theory for the impact of poisoning proportion and regularisation on attack efficacy in linear regression. Through QR stepwise regression, we study the spectral signatures of the Hessian in multi-output regression. We perform experiments on deep networks to show experimentally that this theory extends to modern convolutional and transformer networks under the cross-entropy loss. Based on these insights we develop preliminary algorithms to determine if a network has been poisoned and remedies which do not require further training.
HessFormer: Hessians at Foundation Scale
May 16, 2025

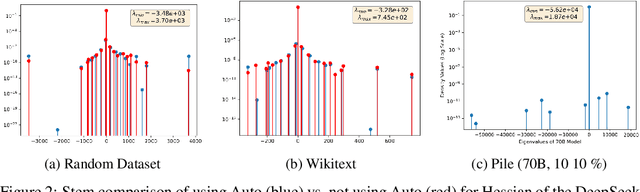
Whilst there have been major advancements in the field of first order optimisation of deep learning models, where state of the art open source mixture of expert models go into the hundreds of billions of parameters, methods that rely on Hessian vector products, are still limited to run on a single GPU and thus cannot even work for models in the billion parameter range. We release a software package \textbf{HessFormer}, which integrates nicely with the well known Transformers package and allows for distributed hessian vector computation across a single node with multiple GPUs. Underpinning our implementation is a distributed stochastic lanczos quadrature algorithm, which we release for public consumption. Using this package we investigate the Hessian spectral density of the recent Deepseek $70$bn parameter model.
Compute-Optimal LLMs Provably Generalize Better With Scale
Apr 21, 2025



Why do larger language models generalize better? To investigate this question, we develop generalization bounds on the pretraining objective of large language models (LLMs) in the compute-optimal regime, as described by the Chinchilla scaling laws. We introduce a novel, fully empirical Freedman-type martingale concentration inequality that tightens existing bounds by accounting for the variance of the loss function. This generalization bound can be decomposed into three interpretable components: the number of parameters per token, the loss variance, and the quantization error at a fixed bitrate. As compute-optimal language models are scaled up, the number of parameters per data point remains constant; however, both the loss variance and the quantization error decrease, implying that larger models should have smaller generalization gaps. We examine why larger models tend to be more quantizable from an information theoretic perspective, showing that the rate at which they can integrate new information grows more slowly than their capacity on the compute-optimal frontier. From these findings we produce a scaling law for the generalization gap, with bounds that become predictably stronger with scale.
Universal characteristics of deep neural network loss surfaces from random matrix theory
May 17, 2022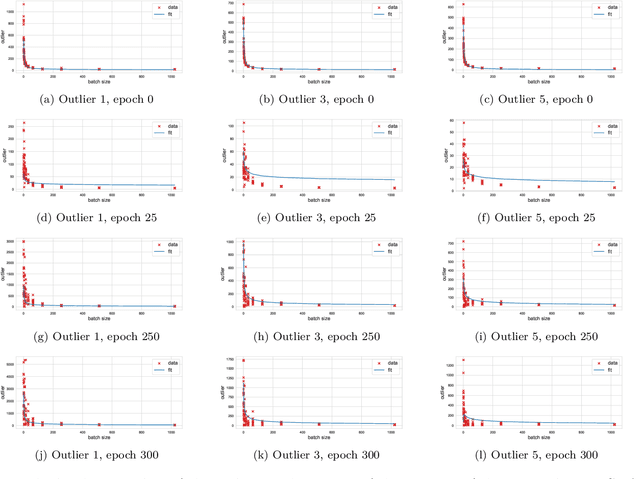
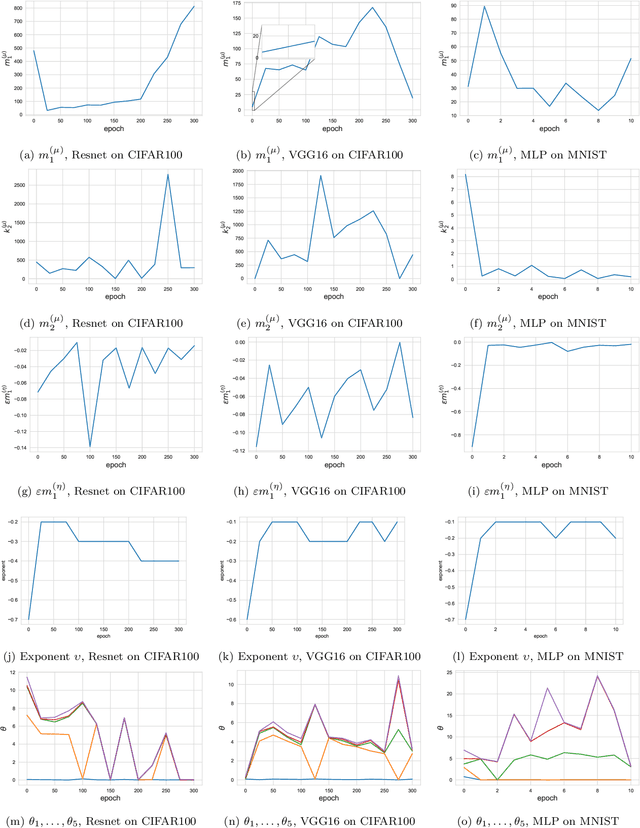
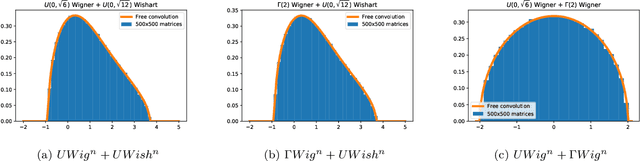
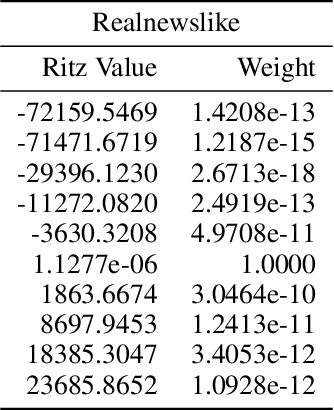
This paper considers several aspects of random matrix universality in deep neural networks. Motivated by recent experimental work, we use universal properties of random matrices related to local statistics to derive practical implications for deep neural networks based on a realistic model of their Hessians. In particular we derive universal aspects of outliers in the spectra of deep neural networks and demonstrate the important role of random matrix local laws in popular pre-conditioning gradient descent algorithms. We also present insights into deep neural network loss surfaces from quite general arguments based on tools from statistical physics and random matrix theory.
Applicability of Random Matrix Theory in Deep Learning
Feb 12, 2021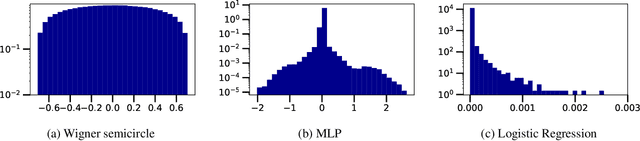
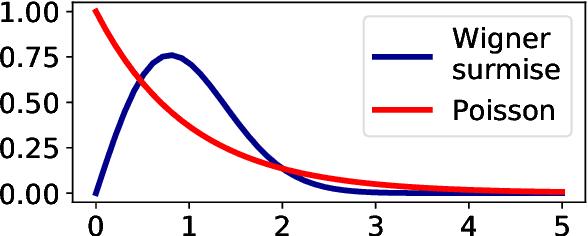
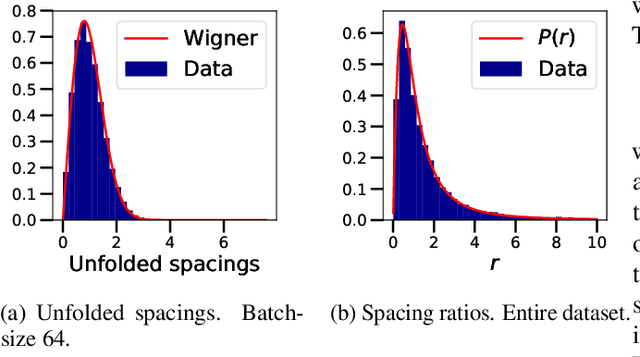
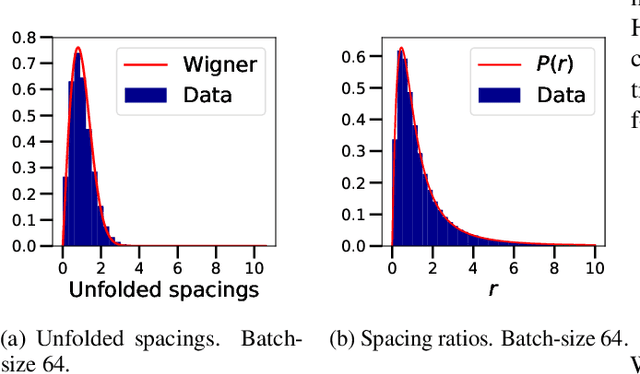
We investigate the local spectral statistics of the loss surface Hessians of artificial neural networks, where we discover excellent agreement with Gaussian Orthogonal Ensemble statistics across several network architectures and datasets. These results shed new light on the applicability of Random Matrix Theory to modelling neural networks and suggest a previously unrecognised role for it in the study of loss surfaces in deep learning. Inspired by these observations, we propose a novel model for the true loss surfaces of neural networks, consistent with our observations, which allows for Hessian spectral densities with rank degeneracy and outliers, extensively observed in practice, and predicts a growing independence of loss gradients as a function of distance in weight-space. We further investigate the importance of the true loss surface in neural networks and find, in contrast to previous work, that the exponential hardness of locating the global minimum has practical consequences for achieving state of the art performance.
Explaining the Adaptive Generalisation Gap
Nov 15, 2020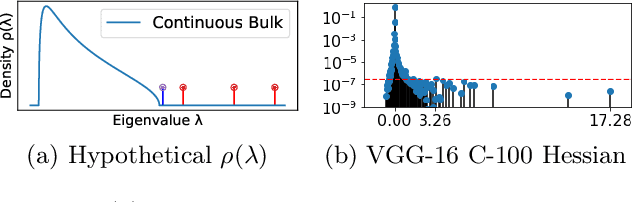

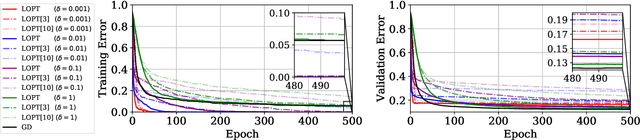
We conjecture that the reason for the difference in generalisation between adaptive and non adaptive gradient methods stems from the failure of adaptive methods to account for the greater levels of noise associated with flatter directions in their estimates of local curvature. This conjecture motivated by results in random matrix theory has implications for optimisation in both simple convex settings and deep neural networks. We demonstrate that typical schedules used for adaptive methods (with low numerical stability or damping constants) serve to bias relative movement towards flat directions relative to sharp directions, effectively amplifying the noise-to-signal ratio and harming generalisation. We show that the numerical stability/damping constant used in these methods can be decomposed into a learning rate reduction and linear shrinkage of the estimated curvature matrix. We then demonstrate significant generalisation improvements by increasing the shrinkage coefficient, closing the generalisation gap entirely in our neural network experiments. Finally, we show that other popular modifications to adaptive methods, such as decoupled weight decay and partial adaptivity can be shown to calibrate parameter updates to make better use of sharper, more reliable directions.
Curvature is Key: Sub-Sampled Loss Surfaces and the Implications for Large Batch Training
Jun 16, 2020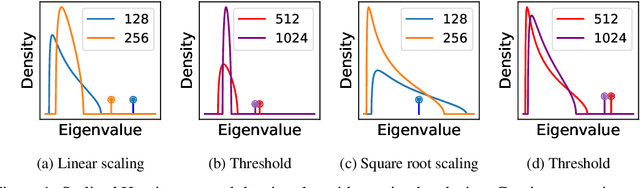
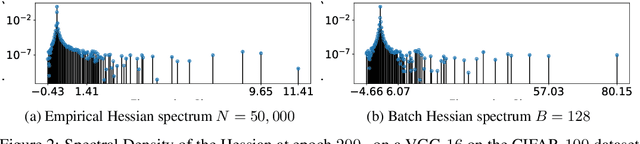
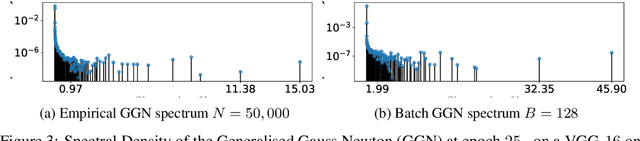
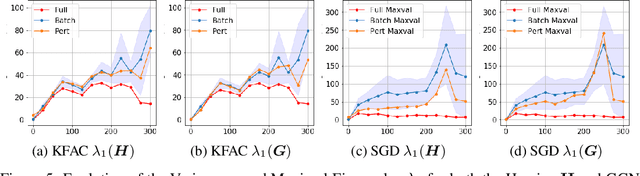
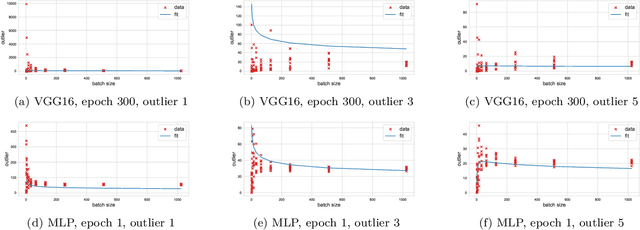
We study the effect of mini-batching on the loss landscape of deep neural networks using spiked, field-dependent random matrix theory. We show that the magnitude of the extremal values of the batch Hessian are larger than those of the empirical Hessian. Our framework yields an analytical expression for the maximal SGD learning rate as a function of batch size, informing practical optimisation schemes. We use this framework to demonstrate that accepted and empirically-proven schemes for adapting the learning rate emerge as special cases of our more general framework. For stochastic second order methods and adaptive methods, we derive that the minimal damping coefficient is proportional to the ratio of the learning rate to batch size. For adaptive methods, we show that for the typical setup of small learning rate and small damping, square root learning rate scalings with increasing batch-size should be employed. We validate our claims on the VGG/WideResNet architectures on the CIFAR-$100$ and ImageNet datasets.
Flatness is a False Friend
Jun 16, 2020
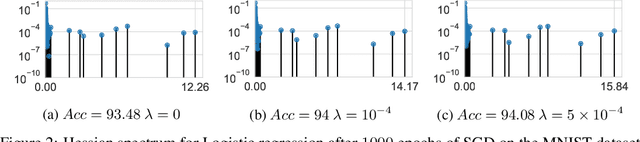
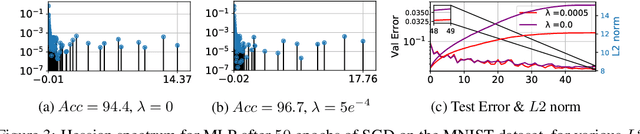
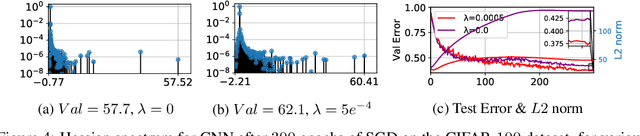
Hessian based measures of flatness, such as the trace, Frobenius and spectral norms, have been argued, used and shown to relate to generalisation. In this paper we demonstrate that for feed forward neural networks under the cross entropy loss, we would expect low loss solutions with large weights to have small Hessian based measures of flatness. This implies that solutions obtained using $L2$ regularisation should in principle be sharper than those without, despite generalising better. We show this to be true for logistic regression, multi-layer perceptrons, simple convolutional, pre-activated and wide residual networks on the MNIST and CIFAR-$100$ datasets. Furthermore, we show that for adaptive optimisation algorithms using iterate averaging, on the VGG-$16$ network and CIFAR-$100$ dataset, achieve superior generalisation to SGD but are $30 \times$ sharper. This theoretical finding, along with experimental results, raises serious questions about the validity of Hessian based sharpness measures in the discussion of generalisation. We further show that the Hessian rank can be bounded by the a constant times number of neurons multiplied by the number of classes, which in practice is often a small fraction of the network parameters. This explains the curious observation that many Hessian eigenvalues are either zero or very near zero which has been reported in the literature.