 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random Matrix Theory for Deep Networks
Paper and Code
Jun 13, 2020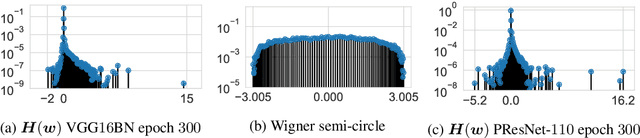



We investigate whether the Wigner semi-circle and Marcenko-Pastur distributions, often used for deep neural network theoretical analysis, match empirically observed spectral densities. We find that even allowing for outliers, the observed spectral shapes strongly deviate from such theoretical predictions. This raises major questions about the usefulness of these models in deep learning. We further show that theoretical results, such as the layered nature of critical points, are strongly dependent on the use of the exact form of these limiting spectral densities. We consider two new classes of matrix ensembles; random Wigner/Wishart ensemble products and percolated Wigner/Wishart ensembles, both of which better match observed spectra. They also give large discrete spectral peaks at the origin, providing a theoretical explanation for the observation that various optima can be connected by one dimensional of low loss values. We further show that, in the case of a random matrix product, the weight of the discrete spectral component at $0$ depends on the ratio of the dimensions of the weight matrices.