 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom matrix theory and the loss surfaces of neural networks
Jun 03, 2023Neural network models are one of the most successful approaches to machine learning, enjoying an enormous amount of development and research over recent years and finding concrete real-world applications in almost any conceivable area of science, engineering and modern life in general. The theoretical understanding of neural networks trails significantly behind their practical success and the engineering heuristics that have grown up around them. Random matrix theory provides a rich framework of tools with which aspects of neural network phenomenology can be explored theoretically. In this thesis, we establish significant extensions of prior work using random matrix theory to understand and describe the loss surfaces of large neural networks, particularly generalising to different architectures. Informed by the historical applications of random matrix theory in physics and elsewhere, we establish the presence of local random matrix universality in real neural networks and then utilise this as a modeling assumption to derive powerful and novel results about the Hessians of neural network loss surfaces and their spectra. In addition to these major contributions, we make use of random matrix models for neural network loss surfaces to shed light on modern neural network training approaches and even to derive a novel and effective variant of a popular optimisation algorithm. Overall, this thesis provides important contributions to cement the place of random matrix theory in the theoretical study of modern neural networks, reveals some of the limits of existing approaches and begins the study of an entirely new role for random matrix theory in the theory of deep learning with important experimental discoveries and novel theoretical results based on local random matrix universality.
Universal characteristics of deep neural network loss surfaces from random matrix theory
May 17, 2022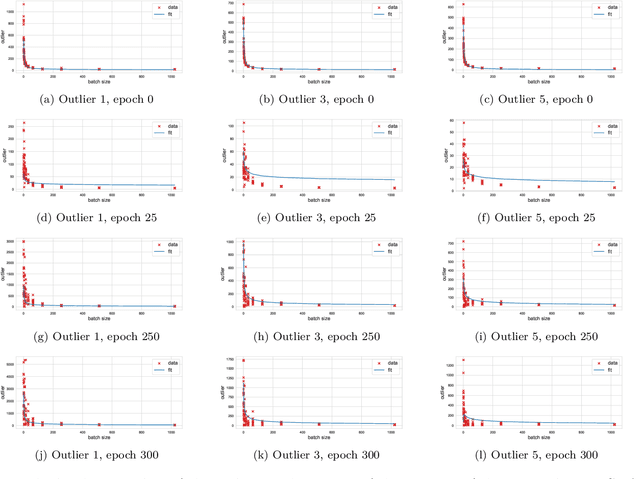
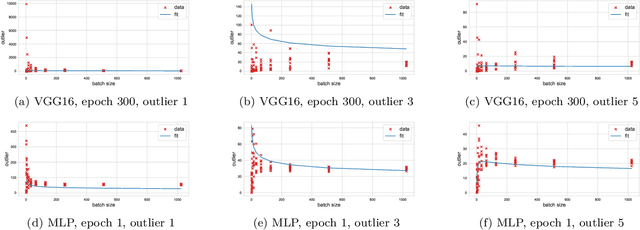
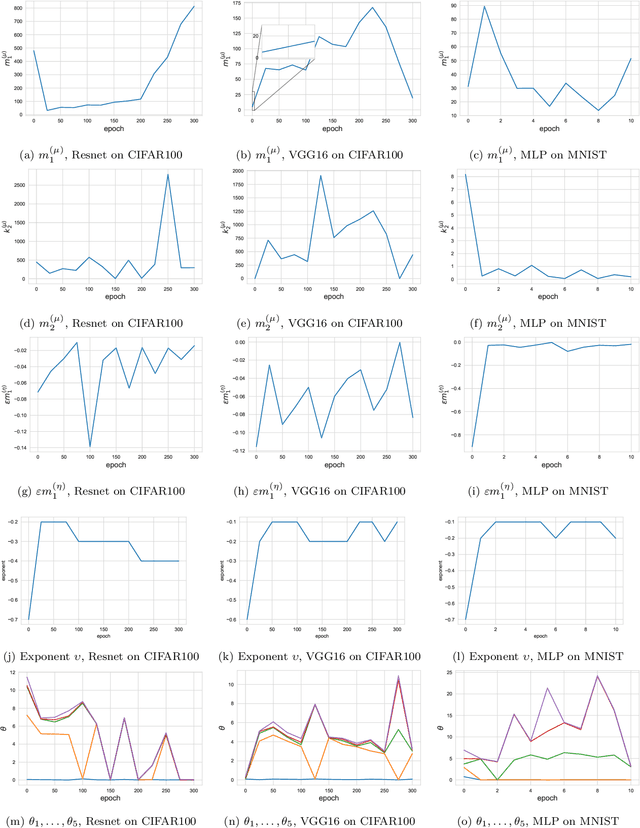
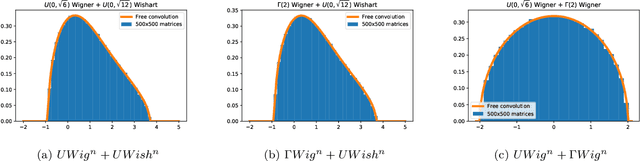
This paper considers several aspects of random matrix universality in deep neural networks. Motivated by recent experimental work, we use universal properties of random matrices related to local statistics to derive practical implications for deep neural networks based on a realistic model of their Hessians. In particular we derive universal aspects of outliers in the spectra of deep neural networks and demonstrate the important role of random matrix local laws in popular pre-conditioning gradient descent algorithms. We also present insights into deep neural network loss surfaces from quite general arguments based on tools from statistical physics and random matrix theory.
A novel sampler for Gauss-Hermite determinantal point processes with application to Monte Carlo integration
Mar 30, 2022
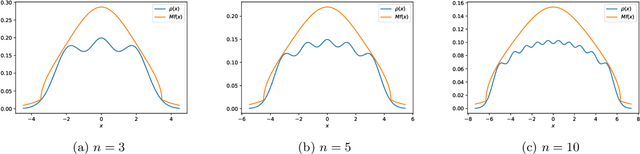
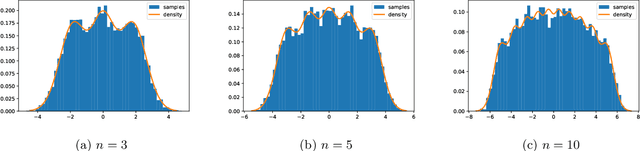
Determinantal points processes are a promising but relatively under-developed tool in machine learning and statistical modelling, being the canonical statistical example of distributions with repulsion. While their mathematical formulation is elegant and appealing, their practical use, such as simply sampling from them, is far from straightforward.Recent work has shown how a particular type of determinantal point process defined on the compact multidimensional space $[-1, 1]^d$ can be practically sampled and further shown how such samples can be used to improve Monte Carlo integration.This work extends those results to a new determinantal point process on $\mathbb{R}^d$ by constructing a novel sampling scheme. Samples from this new process are shown to be useful in Monte Carlo integration against Gaussian measure, which is particularly relevant in machine learning applications.
Applicability of Random Matrix Theory in Deep Learning
Feb 12, 2021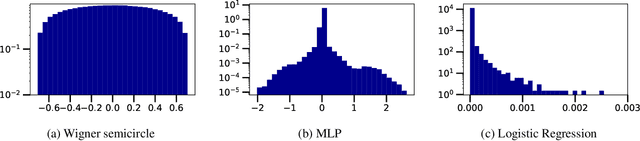
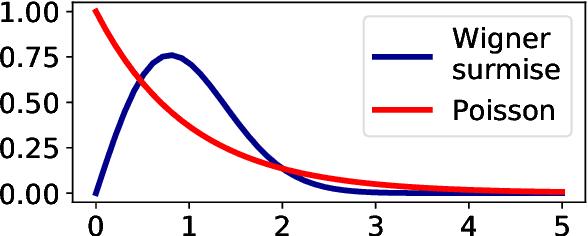
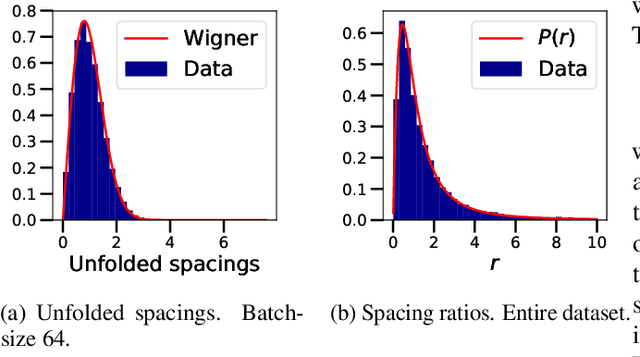
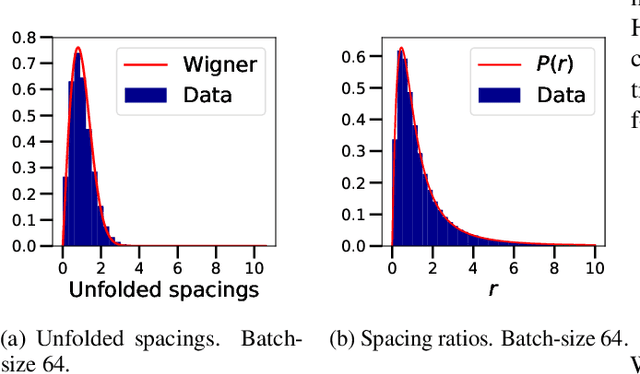
We investigate the local spectral statistics of the loss surface Hessians of artificial neural networks, where we discover excellent agreement with Gaussian Orthogonal Ensemble statistics across several network architectures and datasets. These results shed new light on the applicability of Random Matrix Theory to modelling neural networks and suggest a previously unrecognised role for it in the study of loss surfaces in deep learning. Inspired by these observations, we propose a novel model for the true loss surfaces of neural networks, consistent with our observations, which allows for Hessian spectral densities with rank degeneracy and outliers, extensively observed in practice, and predicts a growing independence of loss gradients as a function of distance in weight-space. We further investigate the importance of the true loss surface in neural networks and find, in contrast to previous work, that the exponential hardness of locating the global minimum has practical consequences for achieving state of the art performance.
A spin-glass model for the loss surfaces of generative adversarial networks
Jan 07, 2021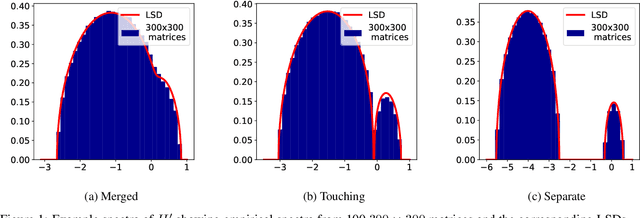
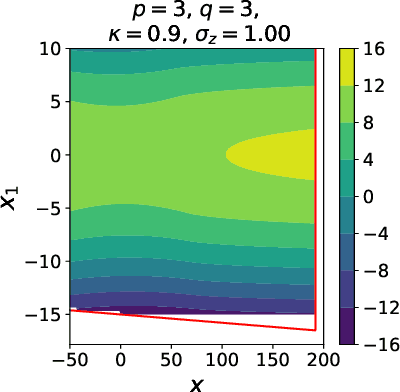
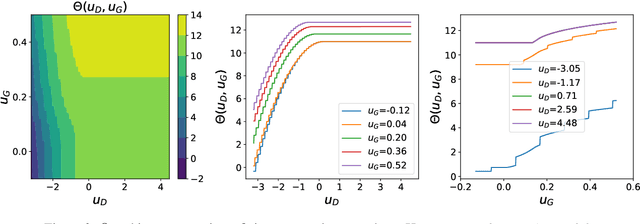
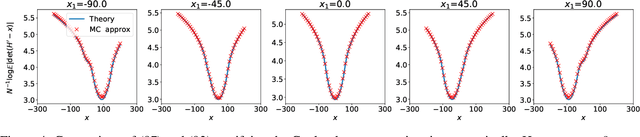
We present a novel mathematical model that seeks to capture the key design feature of generative adversarial networks (GANs). Our model consists of two interacting spin glasses, and we conduct an extensive theoretical analysis of the complexity of the model's critical points using techniques from Random Matrix Theory. The result is insights into the loss surfaces of large GANs that build upon prior insights for simpler networks, but also reveal new structure unique to this setting.