 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterate Averaging Helps: An Alternative Perspective in Deep Learning
Paper and Code



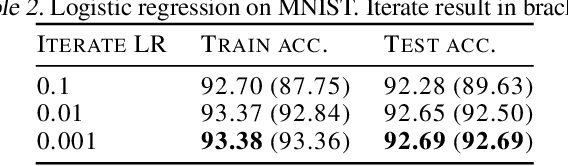
Iterate averaging has a rich history in optimisation, but has only very recently been popularised in deep learning. We investigate its effects in a deep learning context, and argue that previous explanations on its efficacy, which place a high importance on the local geometry (flatness vs sharpness) of final solutions, are not necessarily relevant. We instead argue that the robustness of iterate averaging towards the typically very high estimation noise in deep learning and the various regularisation effects averaging exert, are the key reasons for the performance gain, indeed this effect is made even more prominent due to the over-parameterisation of modern networks. Inspired by this, we propose Gadam, which combines Adam with iterate averaging to address one of key problems of adaptive optimisers that they often generalise worse. Without compromising adaptivity and with minimal additional computational burden, we show that Gadam (and its variant GadamX) achieve a generalisation performance that is consistently superior to tuned SGD and is even on par or better compared to SGD with iterate averaging on various image classification (CIFAR 10/100 and ImageNet 32$\times$32) and language tasks (PTB).