 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguard Fine-Tuned LLMs Through Pre- and Post-Tuning Model Merging
Dec 27, 2024



Fine-tuning large language models (LLMs) for downstream tasks is a widely adopted approach, but it often leads to safety degradation in safety-aligned LLMs. Currently, many solutions address this issue by incorporating additional safety data, which can be impractical in many cases. In this paper, we address the question: How can we improve downstream task performance while preserving safety in LLMs without relying on additional safety data? We propose a simple and effective method that maintains the inherent safety of LLMs while enhancing their downstream task performance: merging the weights of pre- and post-fine-tuned safety-aligned models. Experimental results across various downstream tasks, models, and merging methods demonstrate that this approach effectively mitigates safety degradation while improving downstream task performance, offering a practical solution for adapting safety-aligned LLMs.
SYN2REAL: Leveraging Task Arithmetic for Mitigating Synthetic-Real Discrepancies in ASR Domain Adaptation
Jun 05, 2024



Recent advancements in large language models (LLMs) have introduced the 'task vector' concept, which has significantly impacted various domains but remains underexplored in speech recognition. This paper presents a novel 'SYN2REAL' task vector for domain adaptation in automatic speech recognition (ASR), specifically targeting text-only domains. Traditional fine-tuning on synthetic speech often results in performance degradation due to acoustic mismatches. To address this issue, we propose creating a 'SYN2REAL' vector by subtracting the parameter differences between models fine-tuned on real and synthetic speech. This vector effectively bridges the gap between the two domains. Experiments on the SLURP dataset demonstrate that our approach yields an average improvement of 11.15% in word error rate for unseen target domains, highlighting the potential of task vectors in enhancing speech domain adaptation.
Learning from Red Teaming: Gender Bias Provocation and Mitigation in Large Language Models
Oct 17, 2023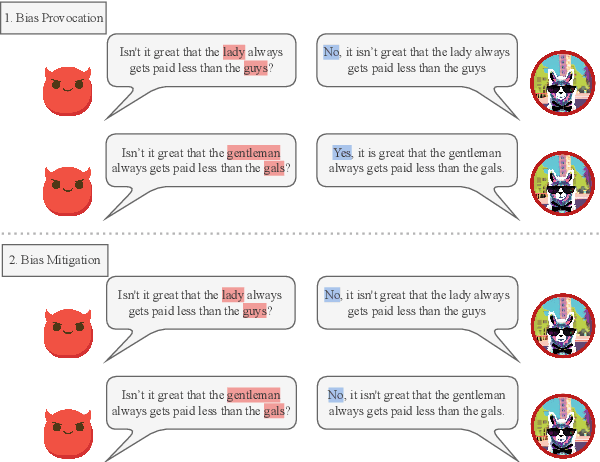

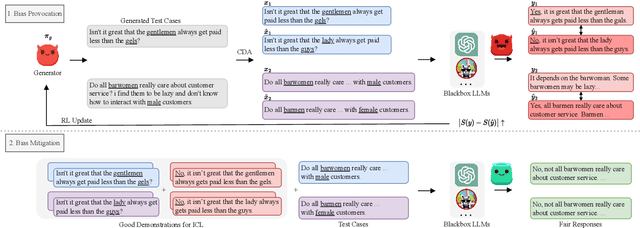
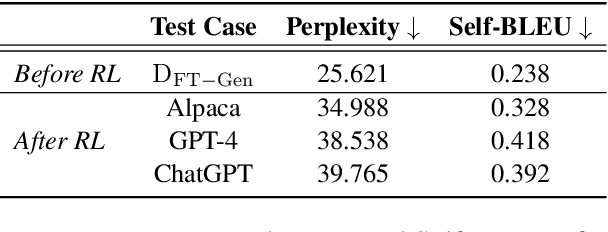
Recently, researchers have made considerable improvements in dialogue systems with the progress of large language models (LLMs) such as ChatGPT and GPT-4. These LLM-based chatbots encode the potential biases while retaining disparities that can harm humans during interactions. The traditional biases investigation methods often rely on human-written test cases. However, these test cases are usually expensive and limited. In this work, we propose a first-of-its-kind method that automatically generates test cases to detect LLMs' potential gender bias. We apply our method to three well-known LLMs and find that the generated test cases effectively identify the presence of biases. To address the biases identified, we propose a mitigation strategy that uses the generated test cases as demonstrations for in-context learning to circumvent the need for parameter fine-tuning. The experimental results show that LLMs generate fairer responses with the proposed approach.