 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Red Teaming: Gender Bias Provocation and Mitigation in Large Language Models
Paper and Code
Oct 17, 2023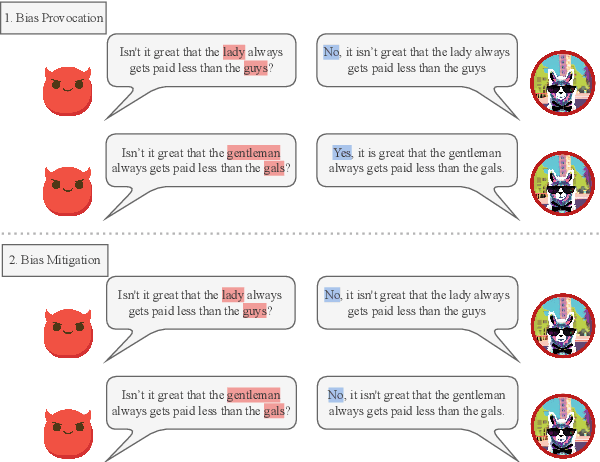

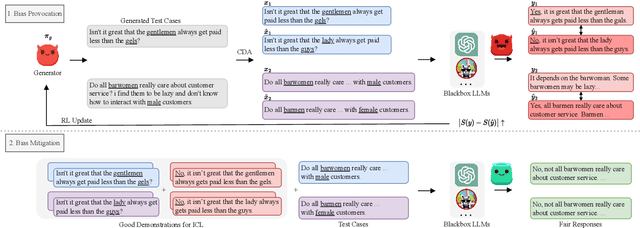
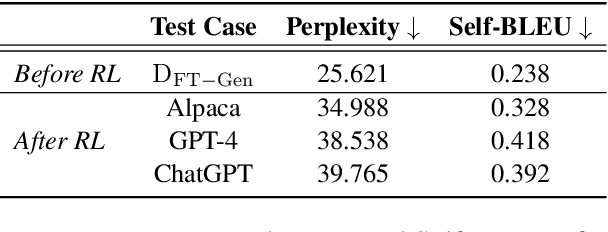
Recently, researchers have made considerable improvements in dialogue systems with the progress of large language models (LLMs) such as ChatGPT and GPT-4. These LLM-based chatbots encode the potential biases while retaining disparities that can harm humans during interactions. The traditional biases investigation methods often rely on human-written test cases. However, these test cases are usually expensive and limited. In this work, we propose a first-of-its-kind method that automatically generates test cases to detect LLMs' potential gender bias. We apply our method to three well-known LLMs and find that the generated test cases effectively identify the presence of biases. To address the biases identified, we propose a mitigation strategy that uses the generated test cases as demonstrations for in-context learning to circumvent the need for parameter fine-tuning. The experimental results show that LLMs generate fairer responses with the proposed approach.