 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Natural Supervision for Language Representation Learning and Generation
Paper and Code
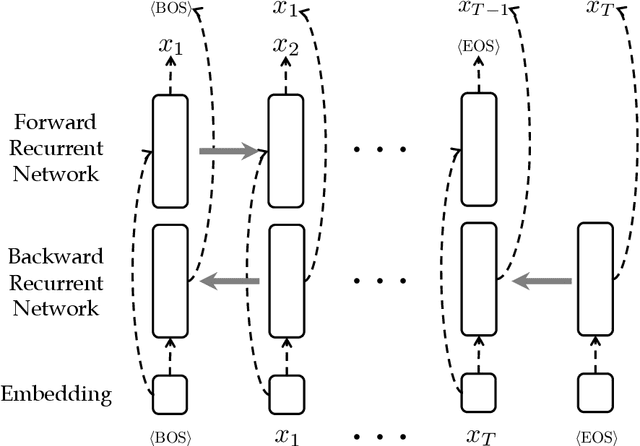
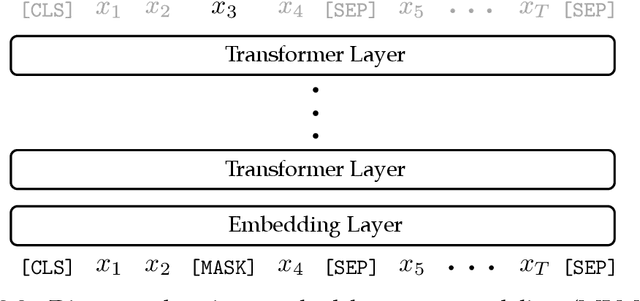
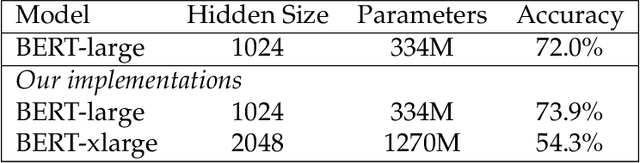
Recent breakthroughs in Natural Language Processing (NLP) have been driven by language models trained on a massive amount of plain text. While powerful, deriving supervision from textual resources is still an open question. For example, language model pretraining often neglects the rich, freely-available structures in textual data. In this thesis, we describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision. We first investigate self-supervised training losses to help enhance the performance of pretrained language models for various NLP tasks. Specifically, we alter the sentence prediction loss to make it better suited to other pretraining losses and more challenging to solve. We design an intermediate finetuning step that uses self-supervised training to promote models' ability in cross-task generalization. Then we describe methods to leverage the structures in Wikipedia and paraphrases. In particular, we propose training losses to exploit hyperlinks, article structures, and article category graphs for entity-, discourse-, entailment-related knowledge. We propose a framework that uses paraphrase pairs to disentangle semantics and syntax in sentence representations. We extend the framework for a novel generation task that controls the syntax of output text with a sentential exemplar. Lastly, we discuss our work on tailoring textual resources for establishing challenging evaluation tasks. We introduce three datasets by defining novel tasks using various fan-contributed websites, including a long-form data-to-text generation dataset, a screenplay summarization dataset, and a long-form story generation dataset. These datasets have unique characteristics offering challenges to future work in their respective task settings.