 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Constructing a Corpus for Studying the Effects of Treatments and Substances Reported in PubMed Abstracts
Paper and Code
Dec 04, 2019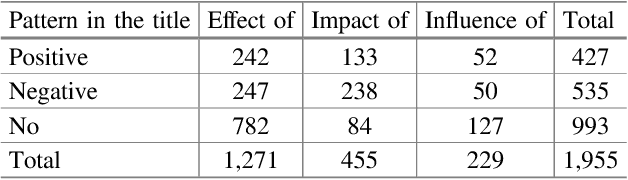

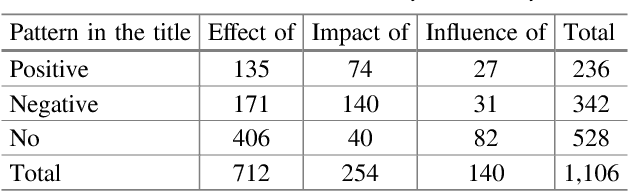

We present the construction of an annotated corpus of PubMed abstracts reporting about positive, negative or neutral effects of treatments or substances. Our ultimate goal is to annotate one sentence (rationale) for each abstract and to use this resource as a training set for text classification of effects discussed in PubMed abstracts. Currently, the corpus consists of 750 abstracts. We describe the automatic processing that supports the corpus construction, the manual annotation activities and some features of the medical language in the abstracts selected for the annotated corpus. It turns out that recognizing the terminology and the abbreviations is key for determining the rationale sentence. The corpus will be applied to improve our classifier, which currently has accuracy of 78.80% achieved with normalization of the abstract terms based on UMLS concepts from specific semantic groups and an SVM with a linear kernel. Finally, we discuss some other possible applications of this corpus.