 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation by Concatenation for Low-Resource Translation: A Mystery and a Solution
May 04, 2021
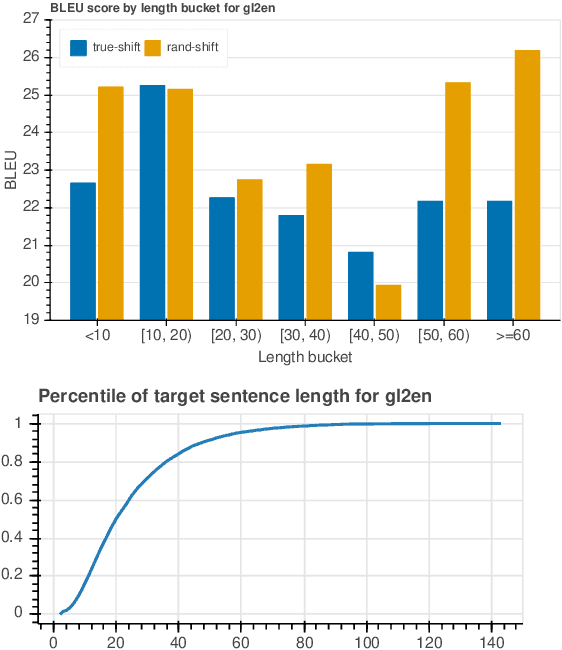

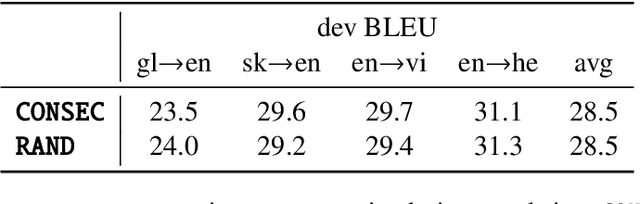
In this paper, we investigate the driving factors behind concatenation, a simple but effective data augmentation method for low-resource neural machine translation. Our experiments suggest that discourse context is unlikely the cause for the improvement of about +1 BLEU across four language pairs. Instead, we demonstrate that the improvement comes from three other factors unrelated to discourse: context diversity, length diversity, and (to a lesser extent) position shifting.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
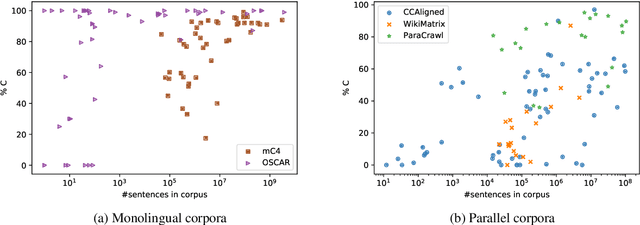

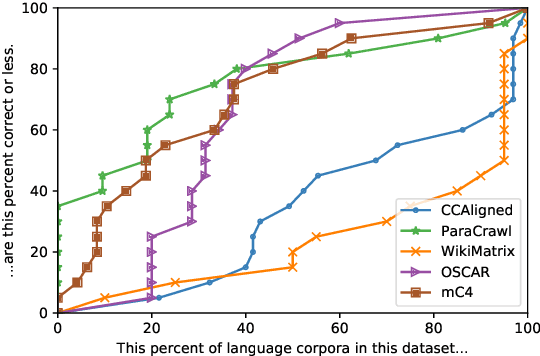
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
Pseudolikelihood Reranking with Masked Language Models
Oct 31, 2019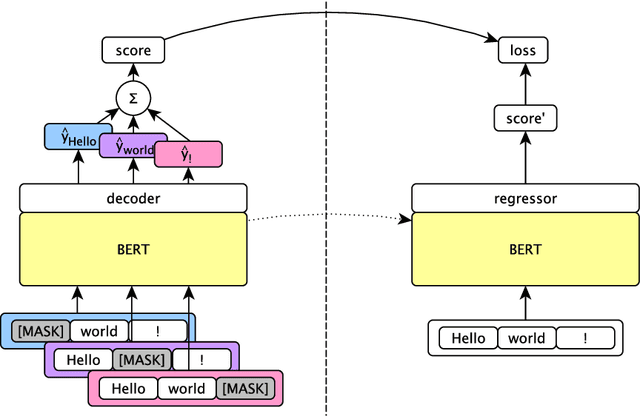
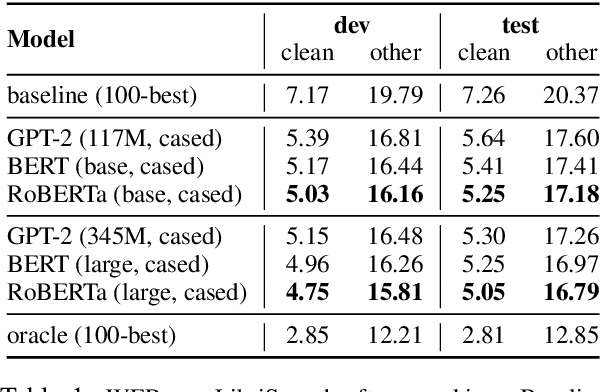
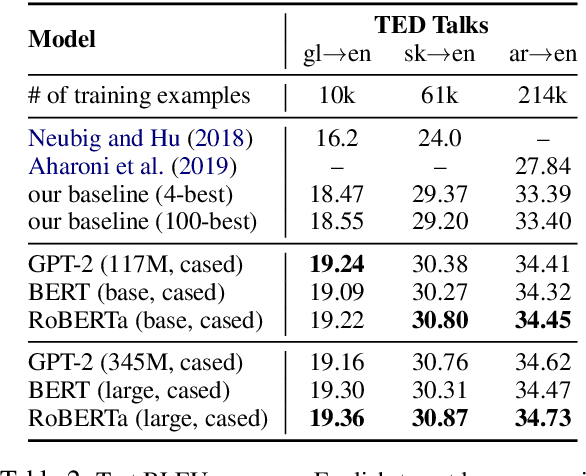
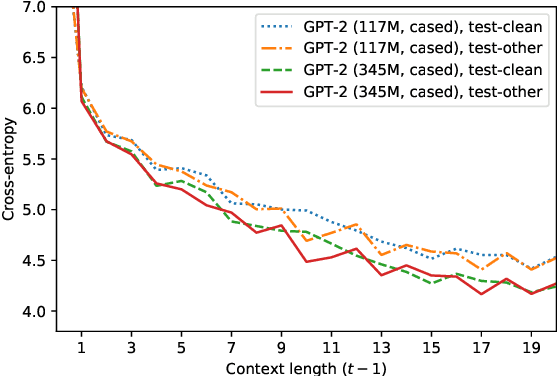
We rerank with scores from pretrained masked language models like BERT to improve ASR and NMT performance. These log-pseudolikelihood scores (LPLs) can outperform large, autoregressive language models (GPT-2) in out-of-the-box scoring. RoBERTa reduces WER by up to 30% relative on an end-to-end LibriSpeech system and adds up to +1.7 BLEU on state-of-the-art baselines for TED Talks low-resource pairs, with further gains from domain adaptation. In the multilingual setting, a single XLM can be used to rerank translation outputs in multiple languages. The numerical and qualitative properties of LPL scores suggest that LPLs capture sentence fluency better than autoregressive scores. Finally, we finetune BERT to estimate sentence LPLs without masking, enabling scoring in a single, non-recurrent inference pass.
Transformers without Tears: Improving the Normalization of Self-Attention
Oct 14, 2019
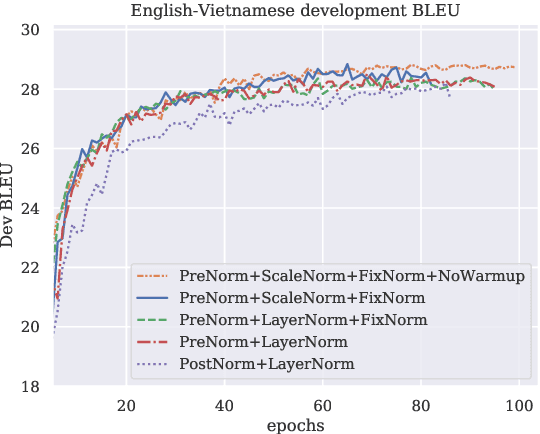
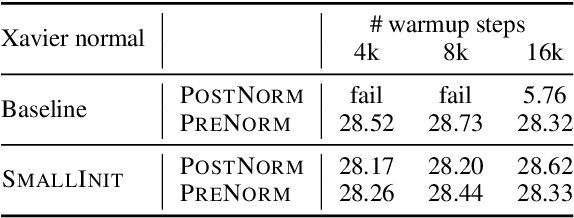
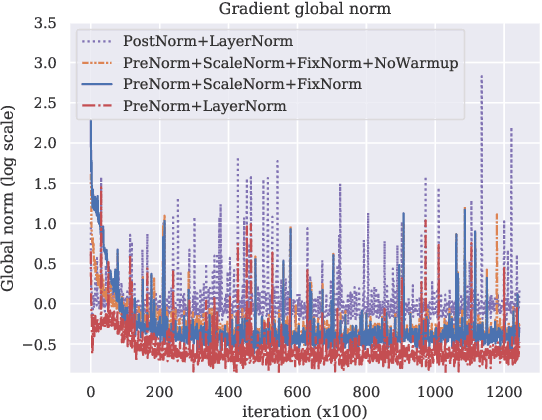
We evaluate three simple, normalization-centric changes to improve Transformer training. First, we show that pre-norm residual connections (PreNorm) and smaller initializations enable warmup-free, validation-based training with large learning rates. Second, we propose $\ell_2$ normalization with a single scale parameter (ScaleNorm) for faster training and better performance. Finally, we reaffirm the effectiveness of normalizing word embeddings to a fixed length (FixNorm). On five low-resource translation pairs from TED Talks-based corpora, these changes always converge, giving an average +1.1 BLEU over state-of-the-art bilingual baselines and a new 32.8 BLEU on IWSLT'15 English-Vietnamese. We observe sharper performance curves, more consistent gradient norms, and a linear relationship between activation scaling and decoder depth. Surprisingly, in the high-resource setting (WMT'14 English-German), ScaleNorm and FixNorm remain competitive but PreNorm degrades performance.
Auto-Sizing the Transformer Network: Improving Speed, Efficiency, and Performance for Low-Resource Machine Translation
Oct 01, 2019
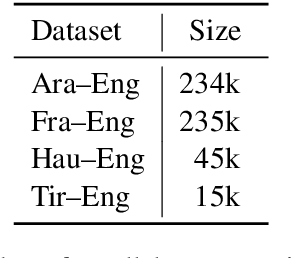
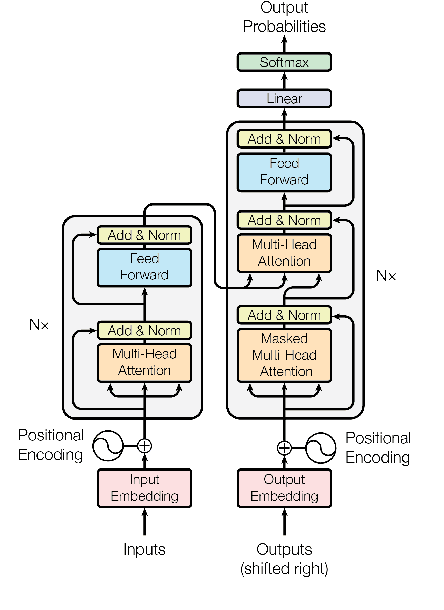
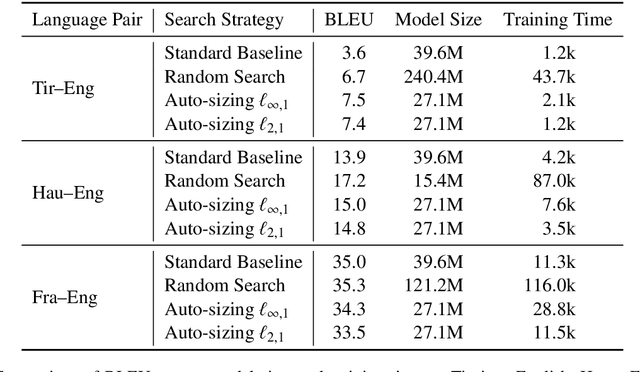
Neural sequence-to-sequence models, particularly the Transformer, are the state of the art in machine translation. Yet these neural networks are very sensitive to architecture and hyperparameter settings. Optimizing these settings by grid or random search is computationally expensive because it requires many training runs. In this paper, we incorporate architecture search into a single training run through auto-sizing, which uses regularization to delete neurons in a network over the course of training. On very low-resource language pairs, we show that auto-sizing can improve BLEU scores by up to 3.9 points while removing one-third of the parameters from the model.
Improving Lexical Choice in Neural Machine Translation
Apr 17, 2018



We explore two solutions to the problem of mistranslating rare words in neural machine translation. First, we argue that the standard output layer, which computes the inner product of a vector representing the context with all possible output word embeddings, rewards frequent words disproportionately, and we propose to fix the norms of both vectors to a constant value. Second, we integrate a simple lexical module which is jointly trained with the rest of the model. We evaluate our approaches on eight language pairs with data sizes ranging from 100k to 8M words, and achieve improvements of up to +4.3 BLEU, surpassing phrase-based translation in nearly all settings.