 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers without Tears: Improving the Normalization of Self-Attention
Paper and Code

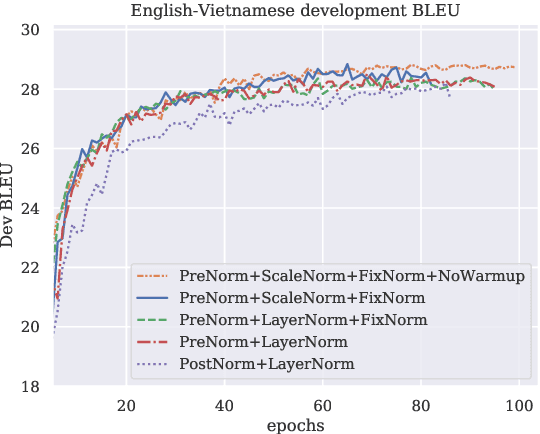
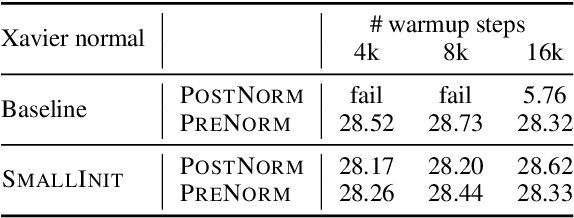
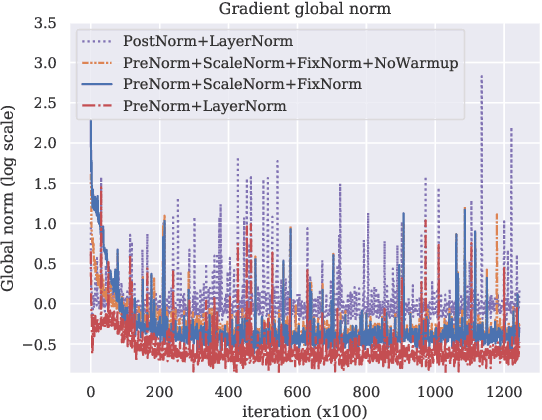
We evaluate three simple, normalization-centric changes to improve Transformer training. First, we show that pre-norm residual connections (PreNorm) and smaller initializations enable warmup-free, validation-based training with large learning rates. Second, we propose $\ell_2$ normalization with a single scale parameter (ScaleNorm) for faster training and better performance. Finally, we reaffirm the effectiveness of normalizing word embeddings to a fixed length (FixNorm). On five low-resource translation pairs from TED Talks-based corpora, these changes always converge, giving an average +1.1 BLEU over state-of-the-art bilingual baselines and a new 32.8 BLEU on IWSLT'15 English-Vietnamese. We observe sharper performance curves, more consistent gradient norms, and a linear relationship between activation scaling and decoder depth. Surprisingly, in the high-resource setting (WMT'14 English-German), ScaleNorm and FixNorm remain competitive but PreNorm degrades performance.