 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudolikelihood Reranking with Masked Language Models
Paper and Code
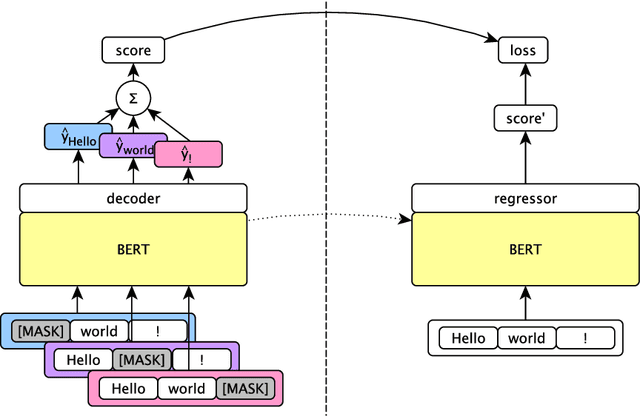
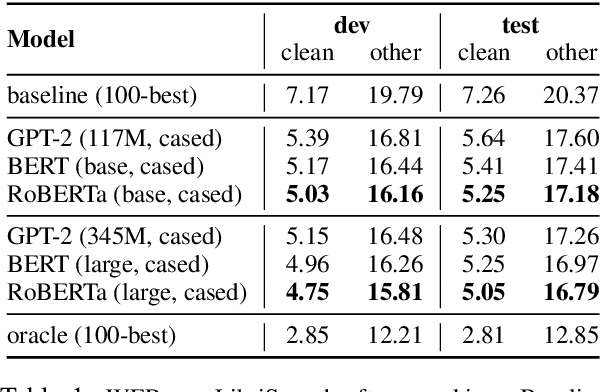
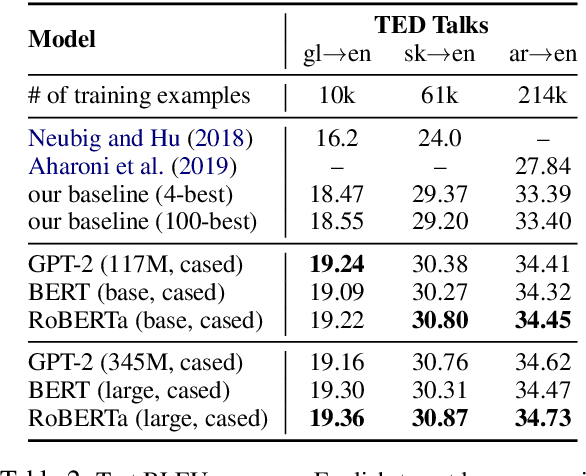
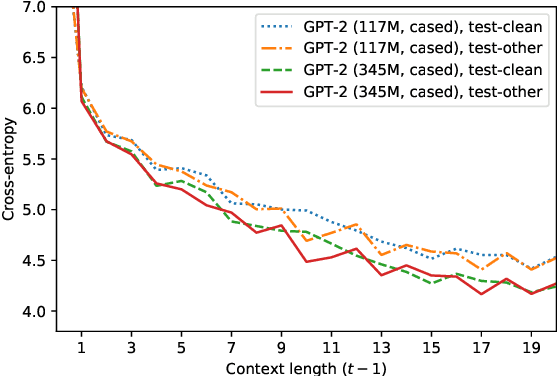
We rerank with scores from pretrained masked language models like BERT to improve ASR and NMT performance. These log-pseudolikelihood scores (LPLs) can outperform large, autoregressive language models (GPT-2) in out-of-the-box scoring. RoBERTa reduces WER by up to 30% relative on an end-to-end LibriSpeech system and adds up to +1.7 BLEU on state-of-the-art baselines for TED Talks low-resource pairs, with further gains from domain adaptation. In the multilingual setting, a single XLM can be used to rerank translation outputs in multiple languages. The numerical and qualitative properties of LPL scores suggest that LPLs capture sentence fluency better than autoregressive scores. Finally, we finetune BERT to estimate sentence LPLs without masking, enabling scoring in a single, non-recurrent inference pass.