 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomOpt: A Homotopy-Based Hyperparameter Optimization Method
Aug 07, 2023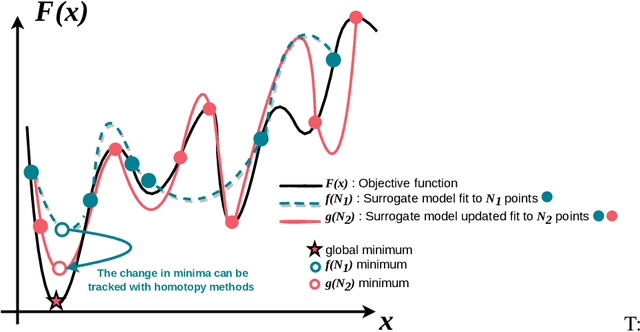



Machine learning has achieved remarkable success over the past couple of decades, often attributed to a combination of algorithmic innovations and the availability of high-quality data available at scale. However, a third critical component is the fine-tuning of hyperparameters, which plays a pivotal role in achieving optimal model performance. Despite its significance, hyperparameter optimization (HPO) remains a challenging task for several reasons. Many HPO techniques rely on naive search methods or assume that the loss function is smooth and continuous, which may not always be the case. Traditional methods, like grid search and Bayesian optimization, often struggle to quickly adapt and efficiently search the loss landscape. Grid search is computationally expensive, while Bayesian optimization can be slow to prime. Since the search space for HPO is frequently high-dimensional and non-convex, it is often challenging to efficiently find a global minimum. Moreover, optimal hyperparameters can be sensitive to the specific dataset or task, further complicating the search process. To address these issues, we propose a new hyperparameter optimization method, HomOpt, using a data-driven approach based on a generalized additive model (GAM) surrogate combined with homotopy optimization. This strategy augments established optimization methodologies to boost the performance and effectiveness of any given method with faster convergence to the optimum on continuous, discrete, and categorical domain spaces. We compare the effectiveness of HomOpt applied to multiple optimization techniques (e.g., Random Search, TPE, Bayes, and SMAC) showing improved objective performance on many standardized machine learning benchmarks and challenging open-set recognition tasks.
Complex Unitary Recurrent Neural Networks using Scaled Cayley Transform
Nov 09, 2018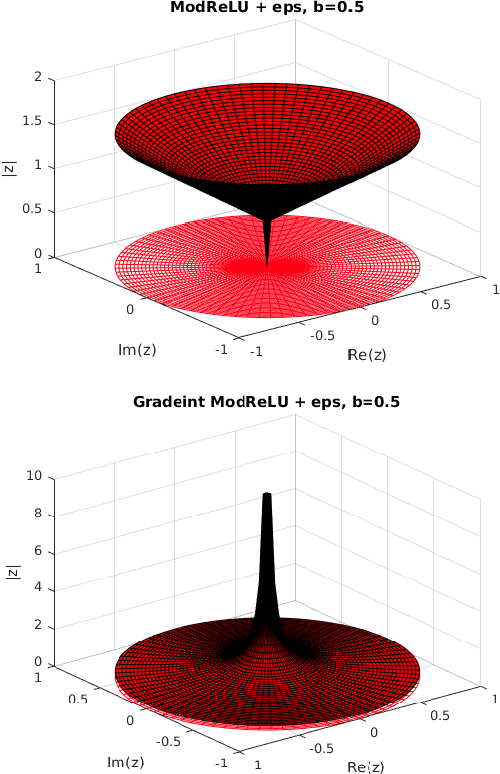


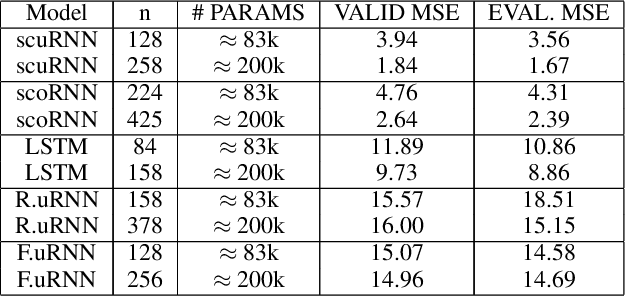
Recurrent neural networks (RNNs) have been successfully used on a wide range of sequential data problems. A well known difficulty in using RNNs is the \textit{vanishing or exploding gradient} problem. Recently, there have been several different RNN architectures that try to mitigate this issue by maintaining an orthogonal or unitary recurrent weight matrix. One such architecture is the scaled Cayley orthogonal recurrent neural network (scoRNN) which parameterizes the orthogonal recurrent weight matrix through a scaled Cayley transform. This parametrization contains a diagonal scaling matrix consisting of positive or negative one entries that can not be optimized by gradient descent. Thus the scaling matrix is fixed before training and a hyperparameter is introduced to tune the matrix for each particular task. In this paper, we develop a unitary RNN architecture based on a complex scaled Cayley transform. Unlike the real orthogonal case, the transformation uses a diagonal scaling matrix consisting of entries on the complex unit circle which can be optimized using gradient descent and no longer requires the tuning of a hyperparameter. We also provide an analysis of a potential issue of the modReLU activiation function which is used in our work and several other unitary RNNs. In the experiments conducted, the scaled Cayley unitary recurrent neural network (scuRNN) achieves comparable or better results than scoRNN and other unitary RNNs without fixing the scaling matrix.