 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Unitary Recurrent Neural Networks using Scaled Cayley Transform
Nov 09, 2018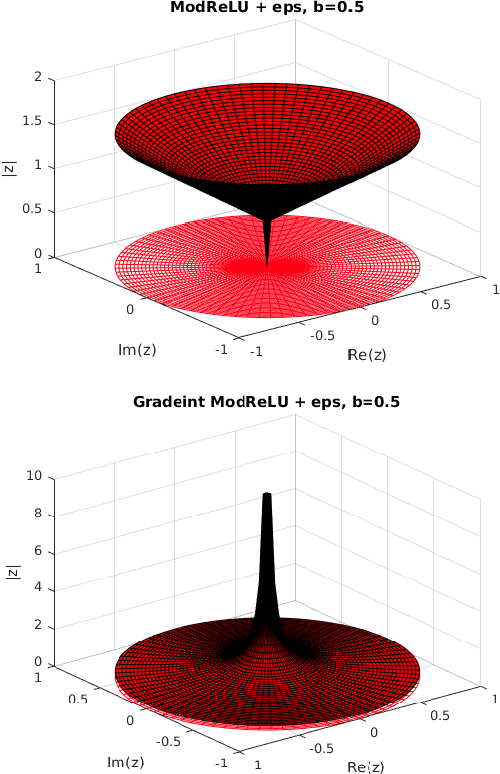


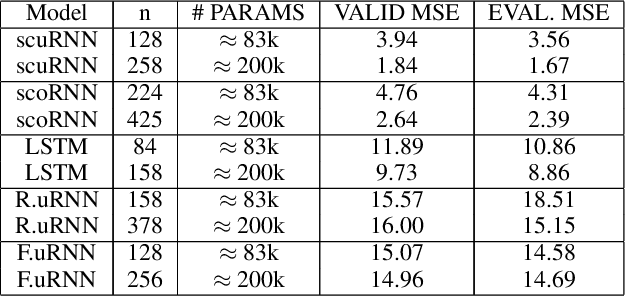
Recurrent neural networks (RNNs) have been successfully used on a wide range of sequential data problems. A well known difficulty in using RNNs is the \textit{vanishing or exploding gradient} problem. Recently, there have been several different RNN architectures that try to mitigate this issue by maintaining an orthogonal or unitary recurrent weight matrix. One such architecture is the scaled Cayley orthogonal recurrent neural network (scoRNN) which parameterizes the orthogonal recurrent weight matrix through a scaled Cayley transform. This parametrization contains a diagonal scaling matrix consisting of positive or negative one entries that can not be optimized by gradient descent. Thus the scaling matrix is fixed before training and a hyperparameter is introduced to tune the matrix for each particular task. In this paper, we develop a unitary RNN architecture based on a complex scaled Cayley transform. Unlike the real orthogonal case, the transformation uses a diagonal scaling matrix consisting of entries on the complex unit circle which can be optimized using gradient descent and no longer requires the tuning of a hyperparameter. We also provide an analysis of a potential issue of the modReLU activiation function which is used in our work and several other unitary RNNs. In the experiments conducted, the scaled Cayley unitary recurrent neural network (scuRNN) achieves comparable or better results than scoRNN and other unitary RNNs without fixing the scaling matrix.