 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnings from curating a trustworthy, well-annotated, and useful dataset of disordered English speech
Sep 13, 2024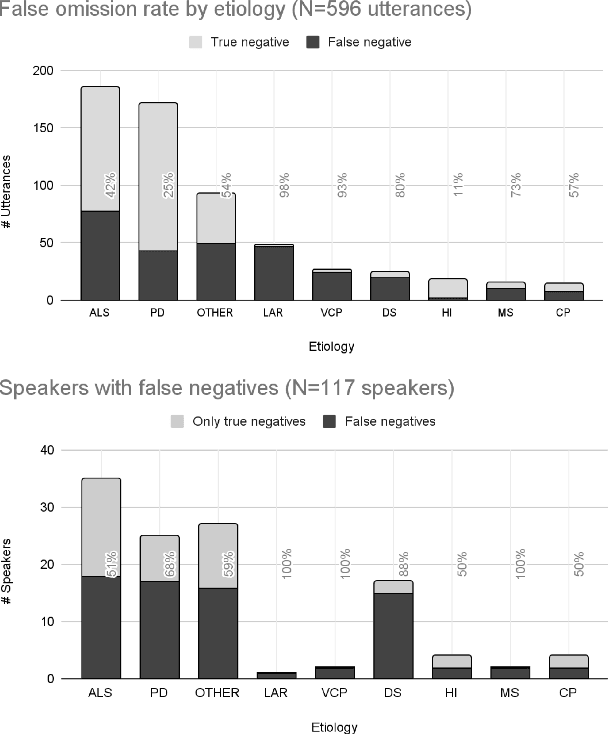
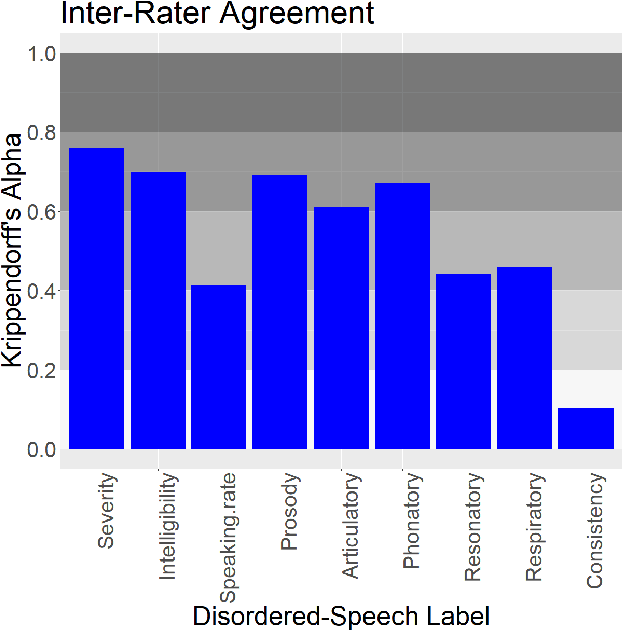
Project Euphonia, a Google initiative, is dedicated to improving automatic speech recognition (ASR) of disordered speech. A central objective of the project is to create a large, high-quality, and diverse speech corpus. This report describes the project's latest advancements in data collection and annotation methodologies, such as expanding speaker diversity in the database, adding human-reviewed transcript corrections and audio quality tags to 350K (of the 1.2M total) audio recordings, and amassing a comprehensive set of metadata (including more than 40 speech characteristic labels) for over 75\% of the speakers in the database. We report on the impact of transcript corrections on our machine-learning (ML) research, inter-rater variability of assessments of disordered speech patterns, and our rationale for gathering speech metadata. We also consider the limitations of using automated off-the-shelf annotation methods for assessing disordered speech.
Using Large Language Models to Accelerate Communication for Users with Severe Motor Impairments
Dec 03, 2023



Finding ways to accelerate text input for individuals with profound motor impairments has been a long-standing area of research. Closing the speed gap for augmentative and alternative communication (AAC) devices such as eye-tracking keyboards is important for improving the quality of life for such individuals. Recent advances in neural networks of natural language pose new opportunities for re-thinking strategies and user interfaces for enhanced text-entry for AAC users. In this paper, we present SpeakFaster, consisting of large language models (LLMs) and a co-designed user interface for text entry in a highly-abbreviated form, allowing saving 57% more motor actions than traditional predictive keyboards in offline simulation. A pilot study with 19 non-AAC participants typing on a mobile device by hand demonstrated gains in motor savings in line with the offline simulation, while introducing relatively small effects on overall typing speed. Lab and field testing on two eye-gaze typing users with amyotrophic lateral sclerosis (ALS) demonstrated text-entry rates 29-60% faster than traditional baselines, due to significant saving of expensive keystrokes achieved through phrase and word predictions from context-aware LLMs. These findings provide a strong foundation for further exploration of substantially-accelerated text communication for motor-impaired users and demonstrate a direction for applying LLMs to text-based user interfaces.