 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Accelerate Communication for Users with Severe Motor Impairments
Dec 03, 2023



Finding ways to accelerate text input for individuals with profound motor impairments has been a long-standing area of research. Closing the speed gap for augmentative and alternative communication (AAC) devices such as eye-tracking keyboards is important for improving the quality of life for such individuals. Recent advances in neural networks of natural language pose new opportunities for re-thinking strategies and user interfaces for enhanced text-entry for AAC users. In this paper, we present SpeakFaster, consisting of large language models (LLMs) and a co-designed user interface for text entry in a highly-abbreviated form, allowing saving 57% more motor actions than traditional predictive keyboards in offline simulation. A pilot study with 19 non-AAC participants typing on a mobile device by hand demonstrated gains in motor savings in line with the offline simulation, while introducing relatively small effects on overall typing speed. Lab and field testing on two eye-gaze typing users with amyotrophic lateral sclerosis (ALS) demonstrated text-entry rates 29-60% faster than traditional baselines, due to significant saving of expensive keystrokes achieved through phrase and word predictions from context-aware LLMs. These findings provide a strong foundation for further exploration of substantially-accelerated text communication for motor-impaired users and demonstrate a direction for applying LLMs to text-based user interfaces.
Context-Aware Abbreviation Expansion Using Large Language Models
May 11, 2022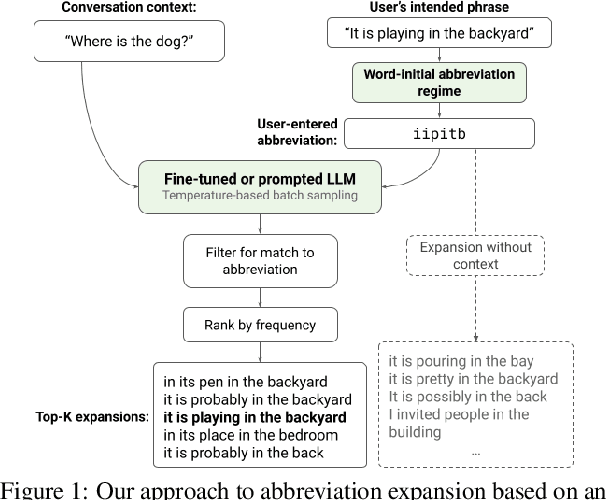


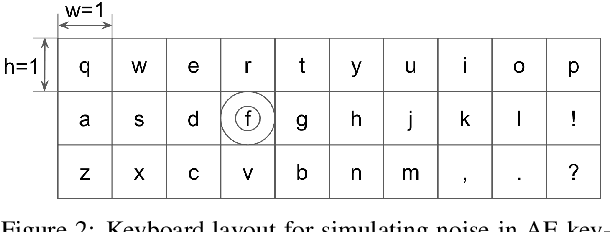
Motivated by the need for accelerating text entry in augmentative and alternative communication (AAC) for people with severe motor impairments, we propose a paradigm in which phrases are abbreviated aggressively as primarily word-initial letters. Our approach is to expand the abbreviations into full-phrase options by leveraging conversation context with the power of pretrained large language models (LLMs). Through zero-shot, few-shot, and fine-tuning experiments on four public conversation datasets, we show that for replies to the initial turn of a dialog, an LLM with 64B parameters is able to exactly expand over 70% of phrases with abbreviation length up to 10, leading to an effective keystroke saving rate of up to about 77% on these exact expansions. Including a small amount of context in the form of a single conversation turn more than doubles abbreviation expansion accuracies compared to having no context, an effect that is more pronounced for longer phrases. Additionally, the robustness of models against typo noise can be enhanced through fine-tuning on noisy data.
When is it right and good for an intelligent autonomous vehicle to take over control ?
Jan 24, 2019
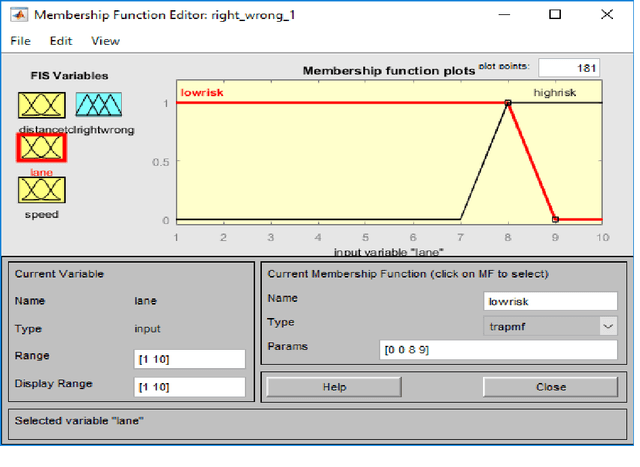
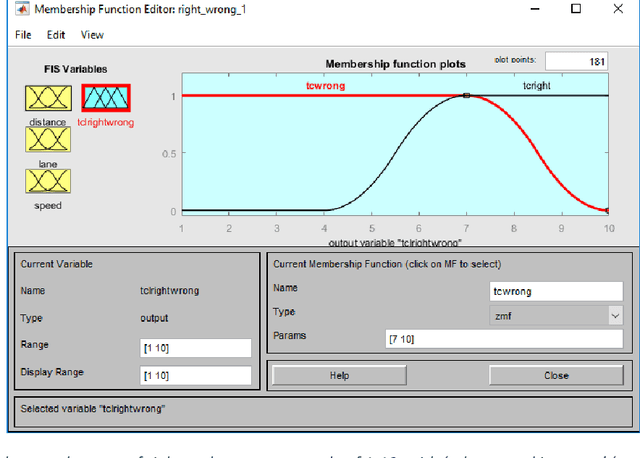

There is much debate in machine ethics about the most appropriate way to introduce ethical reasoning capabilities into intelligent autonomous machines. Recent incidents involving autonomous vehicles in which humans have been killed or injured have raised questions about how we ensure that such vehicles have an ethical dimension to their behaviour and are therefore trustworthy. The main problem is that hardwiring such machines with rules not to cause harm or damage is not consistent with the notion of autonomy and intelligence. Also, such ethical hardwiring does not leave intelligent autonomous machines with any course of action if they encounter situations or dilemmas for which they are not programmed or where some harm is caused no matter what course of action is taken. Teaching machines so that they learn ethics may also be problematic given recent findings in machine learning that machines pick up the prejudices and biases embedded in their learning algorithms or data. This paper describes a fuzzy reasoning approach to machine ethics. The paper shows how it is possible for an ethics architecture to reason when taking over from a human driver is morally justified. The design behind such an ethical reasoner is also applied to an ethical dilemma resolution case. One major advantage of the approach is that the ethical reasoner can generate its own data for learning moral rules (hence, autometric) and thereby reduce the possibility of picking up human biases and prejudices. The results show that a new type of metric-based ethics appropriate for autonomous intelligent machines is feasible and that our current concept of ethical reasoning being largely qualitative in nature may need revising if want to construct future autonomous machines that have an ethical dimension to their reasoning so that they become moral machines.
Bio-inspired data mining: Treating malware signatures as biosequences
Feb 15, 2013
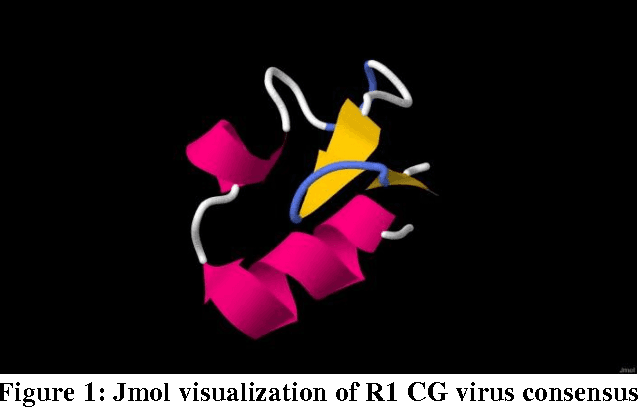
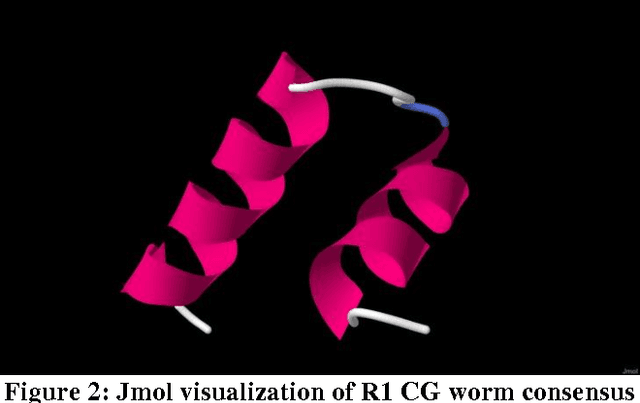

The application of machine learning to bioinformatics problems is well established. Less well understood is the application of bioinformatics techniques to machine learning and, in particular, the representation of non-biological data as biosequences. The aim of this paper is to explore the effects of giving amino acid representation to problematic machine learning data and to evaluate the benefits of supplementing traditional machine learning with bioinformatics tools and techniques. The signatures of 60 computer viruses and 60 computer worms were converted into amino acid representations and first multiply aligned separately to identify conserved regions across different families within each class (virus and worm). This was followed by a second alignment of all 120 aligned signatures together so that non-conserved regions were identified prior to input to a number of machine learning techniques. Differences in length between virus and worm signatures after the first alignment were resolved by the second alignment. Our first set of experiments indicates that representing computer malware signatures as amino acid sequences followed by alignment leads to greater classification and prediction accuracy. Our second set of experiments indicates that checking the results of data mining from artificial virus and worm data against known proteins can lead to generalizations being made from the domain of naturally occurring proteins to malware signatures. However, further work is needed to determine the advantages and disadvantages of different representations and sequence alignment methods for handling problematic machine learning data.