 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-inspired data mining: Treating malware signatures as biosequences
Paper and Code
Feb 15, 2013
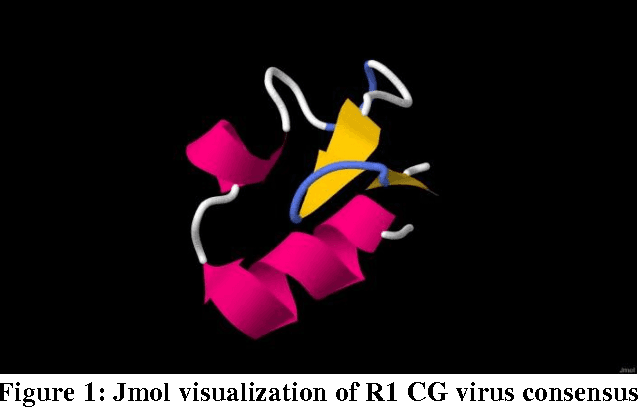
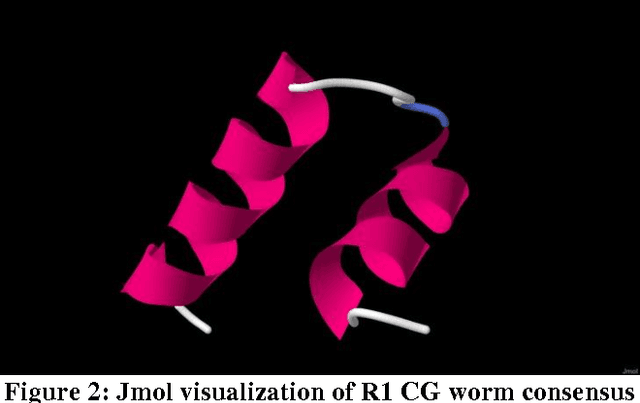

The application of machine learning to bioinformatics problems is well established. Less well understood is the application of bioinformatics techniques to machine learning and, in particular, the representation of non-biological data as biosequences. The aim of this paper is to explore the effects of giving amino acid representation to problematic machine learning data and to evaluate the benefits of supplementing traditional machine learning with bioinformatics tools and techniques. The signatures of 60 computer viruses and 60 computer worms were converted into amino acid representations and first multiply aligned separately to identify conserved regions across different families within each class (virus and worm). This was followed by a second alignment of all 120 aligned signatures together so that non-conserved regions were identified prior to input to a number of machine learning techniques. Differences in length between virus and worm signatures after the first alignment were resolved by the second alignment. Our first set of experiments indicates that representing computer malware signatures as amino acid sequences followed by alignment leads to greater classification and prediction accuracy. Our second set of experiments indicates that checking the results of data mining from artificial virus and worm data against known proteins can lead to generalizations being made from the domain of naturally occurring proteins to malware signatures. However, further work is needed to determine the advantages and disadvantages of different representations and sequence alignment methods for handling problematic machine learning data.