 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Accelerate Communication for Users with Severe Motor Impairments
Dec 03, 2023



Finding ways to accelerate text input for individuals with profound motor impairments has been a long-standing area of research. Closing the speed gap for augmentative and alternative communication (AAC) devices such as eye-tracking keyboards is important for improving the quality of life for such individuals. Recent advances in neural networks of natural language pose new opportunities for re-thinking strategies and user interfaces for enhanced text-entry for AAC users. In this paper, we present SpeakFaster, consisting of large language models (LLMs) and a co-designed user interface for text entry in a highly-abbreviated form, allowing saving 57% more motor actions than traditional predictive keyboards in offline simulation. A pilot study with 19 non-AAC participants typing on a mobile device by hand demonstrated gains in motor savings in line with the offline simulation, while introducing relatively small effects on overall typing speed. Lab and field testing on two eye-gaze typing users with amyotrophic lateral sclerosis (ALS) demonstrated text-entry rates 29-60% faster than traditional baselines, due to significant saving of expensive keystrokes achieved through phrase and word predictions from context-aware LLMs. These findings provide a strong foundation for further exploration of substantially-accelerated text communication for motor-impaired users and demonstrate a direction for applying LLMs to text-based user interfaces.
A Unified View on Neural Message Passing with Opinion Dynamics for Social Networks
Oct 03, 2023Social networks represent a common form of interconnected data frequently depicted as graphs within the domain of deep learning-based inference. These communities inherently form dynamic systems, achieving stability through continuous internal communications and opinion exchanges among social actors along their social ties. In contrast, neural message passing in deep learning provides a clear and intuitive mathematical framework for understanding information propagation and aggregation among connected nodes in graphs. Node representations are dynamically updated by considering both the connectivity and status of neighboring nodes. This research harmonizes concepts from sociometry and neural message passing to analyze and infer the behavior of dynamic systems. Drawing inspiration from opinion dynamics in sociology, we propose ODNet, a novel message passing scheme incorporating bounded confidence, to refine the influence weight of local nodes for message propagation. We adjust the similarity cutoffs of bounded confidence and influence weights of ODNet and define opinion exchange rules that align with the characteristics of social network graphs. We show that ODNet enhances prediction performance across various graph types and alleviates oversmoothing issues. Furthermore, our approach surpasses conventional baselines in graph representation learning and proves its practical significance in analyzing real-world co-occurrence networks of metabolic genes. Remarkably, our method simplifies complex social network graphs solely by leveraging knowledge of interaction frequencies among entities within the system. It accurately identifies internal communities and the roles of genes in different metabolic pathways, including opinion leaders, bridge communicators, and isolators.
Meeting Summarization with Pre-training and Clustering Methods
Nov 16, 2021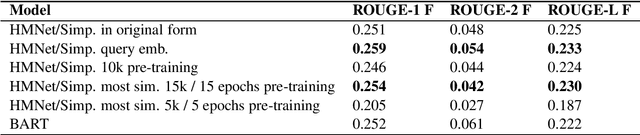


Automatic meeting summarization is becoming increasingly popular these days. The ability to automatically summarize meetings and to extract key information could greatly increase the efficiency of our work and life. In this paper, we experiment with different approaches to improve the performance of query-based meeting summarization. We started with HMNet\cite{hmnet}, a hierarchical network that employs both a word-level transformer and a turn-level transformer, as the baseline. We explore the effectiveness of pre-training the model with a large news-summarization dataset. We investigate adding the embeddings of queries as a part of the input vectors for query-based summarization. Furthermore, we experiment with extending the locate-then-summarize approach of QMSum\cite{qmsum} with an intermediate clustering step. Lastly, we compare the performance of our baseline models with BART, a state-of-the-art language model that is effective for summarization. We achieved improved performance by adding query embeddings to the input of the model, by using BART as an alternative language model, and by using clustering methods to extract key information at utterance level before feeding the text into summarization models.