 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeeting Summarization with Pre-training and Clustering Methods
Nov 16, 2021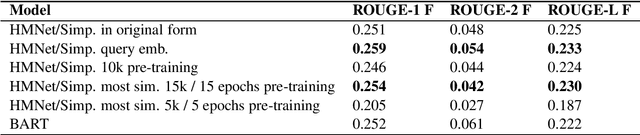


Automatic meeting summarization is becoming increasingly popular these days. The ability to automatically summarize meetings and to extract key information could greatly increase the efficiency of our work and life. In this paper, we experiment with different approaches to improve the performance of query-based meeting summarization. We started with HMNet\cite{hmnet}, a hierarchical network that employs both a word-level transformer and a turn-level transformer, as the baseline. We explore the effectiveness of pre-training the model with a large news-summarization dataset. We investigate adding the embeddings of queries as a part of the input vectors for query-based summarization. Furthermore, we experiment with extending the locate-then-summarize approach of QMSum\cite{qmsum} with an intermediate clustering step. Lastly, we compare the performance of our baseline models with BART, a state-of-the-art language model that is effective for summarization. We achieved improved performance by adding query embeddings to the input of the model, by using BART as an alternative language model, and by using clustering methods to extract key information at utterance level before feeding the text into summarization models.