 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnings from curating a trustworthy, well-annotated, and useful dataset of disordered English speech
Sep 13, 2024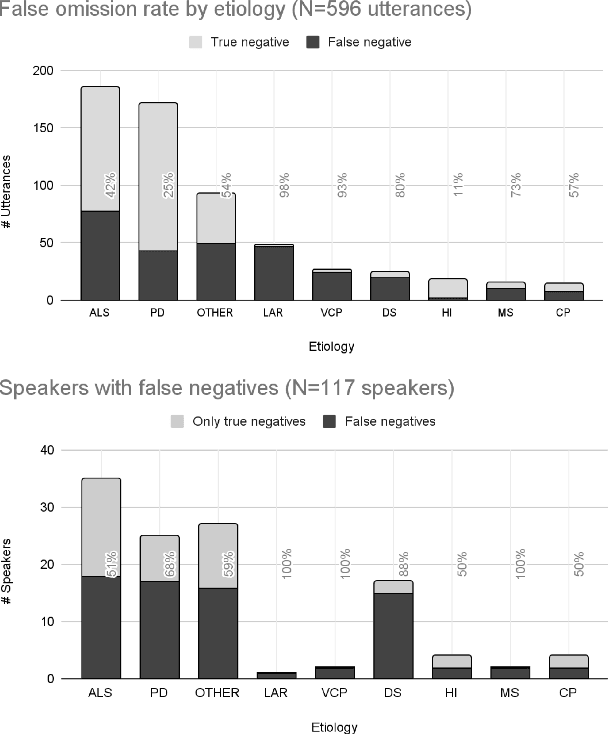
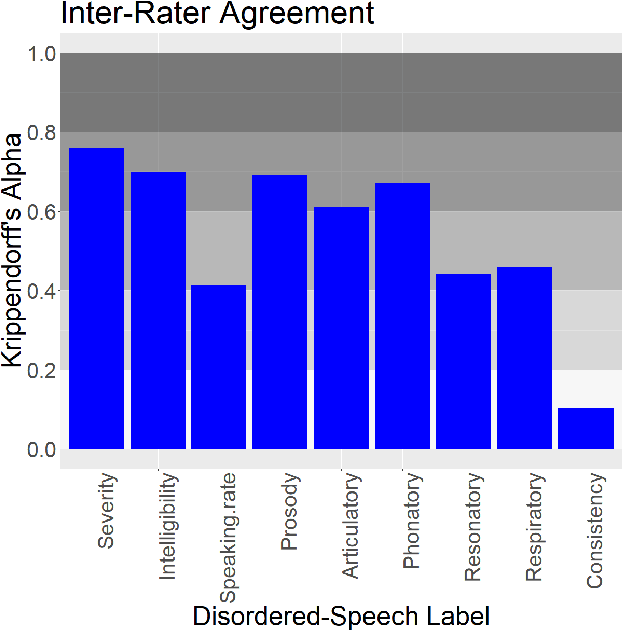
Project Euphonia, a Google initiative, is dedicated to improving automatic speech recognition (ASR) of disordered speech. A central objective of the project is to create a large, high-quality, and diverse speech corpus. This report describes the project's latest advancements in data collection and annotation methodologies, such as expanding speaker diversity in the database, adding human-reviewed transcript corrections and audio quality tags to 350K (of the 1.2M total) audio recordings, and amassing a comprehensive set of metadata (including more than 40 speech characteristic labels) for over 75\% of the speakers in the database. We report on the impact of transcript corrections on our machine-learning (ML) research, inter-rater variability of assessments of disordered speech patterns, and our rationale for gathering speech metadata. We also consider the limitations of using automated off-the-shelf annotation methods for assessing disordered speech.
Speech Intelligibility Classifiers from 550k Disordered Speech Samples
Mar 15, 2023We developed dysarthric speech intelligibility classifiers on 551,176 disordered speech samples contributed by a diverse set of 468 speakers, with a range of self-reported speaking disorders and rated for their overall intelligibility on a five-point scale. We trained three models following different deep learning approaches and evaluated them on ~94K utterances from 100 speakers. We further found the models to generalize well (without further training) on the TORGO database (100% accuracy), UASpeech (0.93 correlation), ALS-TDI PMP (0.81 AUC) datasets as well as on a dataset of realistic unprompted speech we gathered (106 dysarthric and 76 control speakers,~2300 samples).