 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorFlow Eager: A Multi-Stage, Python-Embedded DSL for Machine Learning
Feb 27, 2019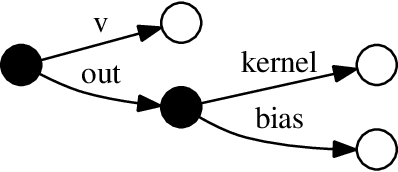

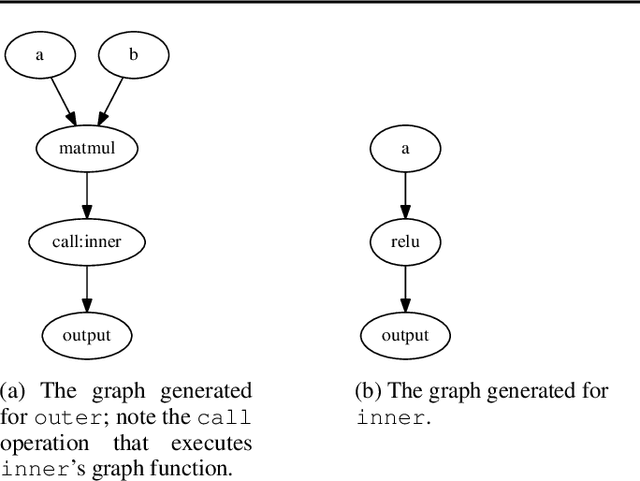
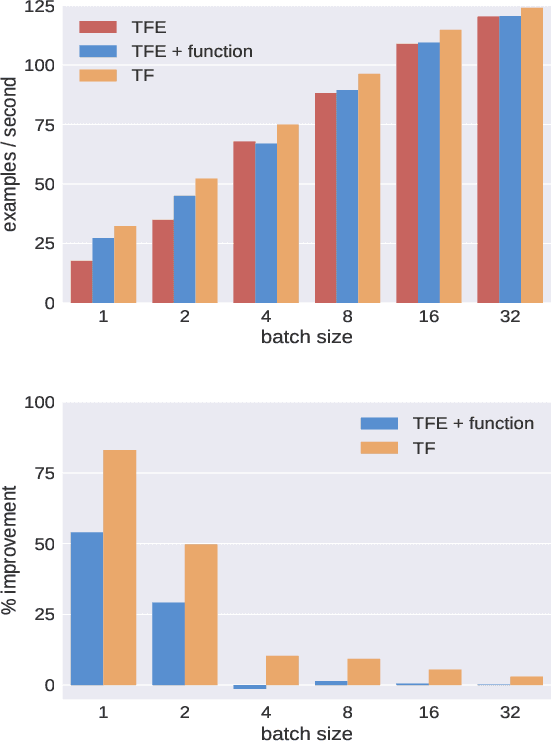
TensorFlow Eager is a multi-stage, Python-embedded domain-specific language for hardware-accelerated machine learning, suitable for both interactive research and production. TensorFlow, which TensorFlow Eager extends, requires users to represent computations as dataflow graphs; this permits compiler optimizations and simplifies deployment but hinders rapid prototyping and run-time dynamism. TensorFlow Eager eliminates these usability costs without sacrificing the benefits furnished by graphs: It provides an imperative front-end to TensorFlow that executes operations immediately and a JIT tracer that translates Python functions composed of TensorFlow operations into executable dataflow graphs. TensorFlow Eager thus offers a multi-stage programming model that makes it easy to interpolate between imperative and staged execution in a single package.
How to show a probabilistic model is better
Feb 11, 2015We present a simple theoretical framework, and corresponding practical procedures, for comparing probabilistic models on real data in a traditional machine learning setting. This framework is based on the theory of proper scoring rules, but requires only basic algebra and probability theory to understand and verify. The theoretical concepts presented are well-studied, primarily in the statistics literature. The goal of this paper is to advocate their wider adoption for performance evaluation in empirical machine learning.
Pushing Your Point of View: Behavioral Measures of Manipulation in Wikipedia
Nov 09, 2011
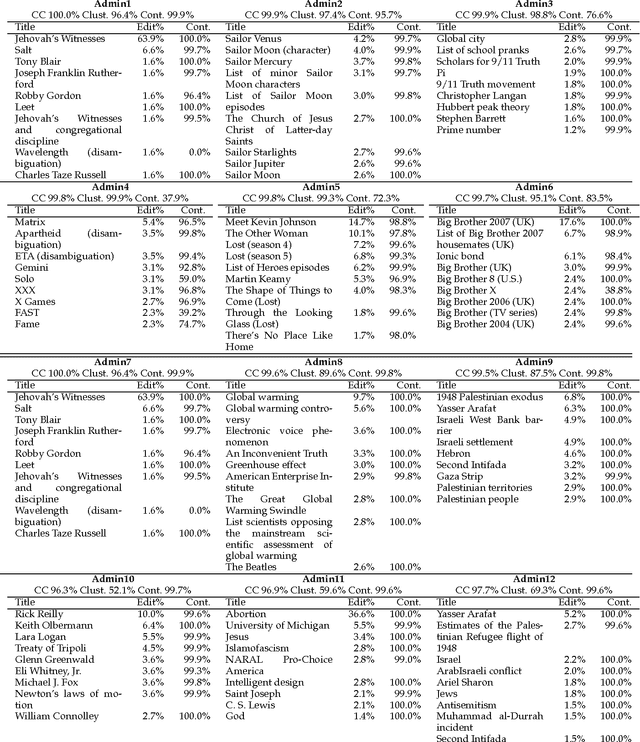
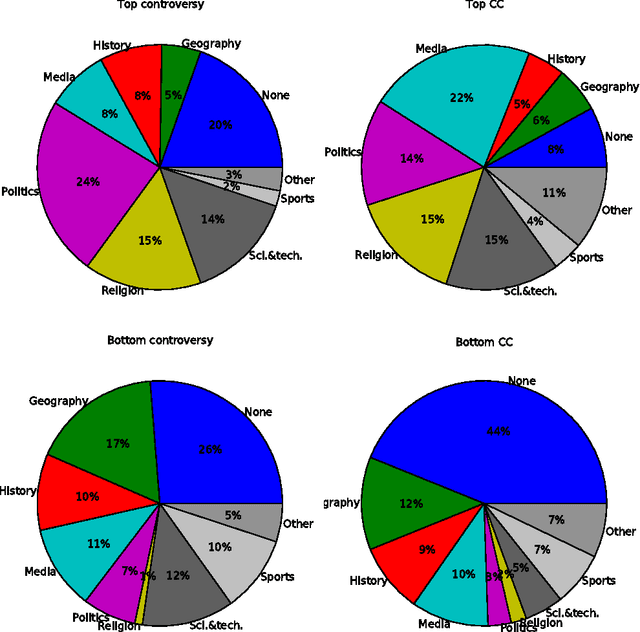
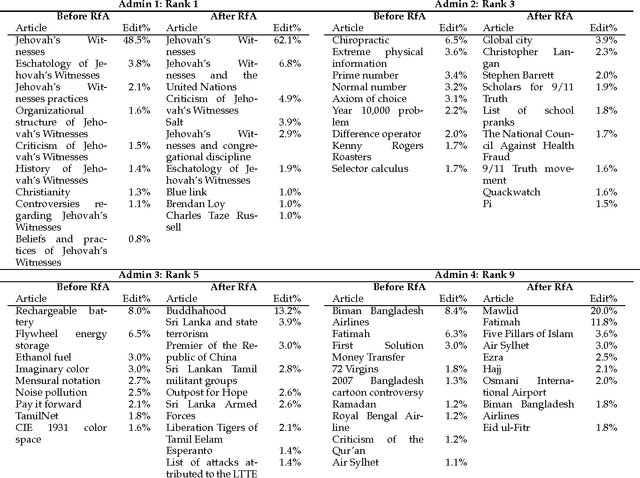
As a major source for information on virtually any topic, Wikipedia serves an important role in public dissemination and consumption of knowledge. As a result, it presents tremendous potential for people to promulgate their own points of view; such efforts may be more subtle than typical vandalism. In this paper, we introduce new behavioral metrics to quantify the level of controversy associated with a particular user: a Controversy Score (C-Score) based on the amount of attention the user focuses on controversial pages, and a Clustered Controversy Score (CC-Score) that also takes into account topical clustering. We show that both these measures are useful for identifying people who try to "push" their points of view, by showing that they are good predictors of which editors get blocked. The metrics can be used to triage potential POV pushers. We apply this idea to a dataset of users who requested promotion to administrator status and easily identify some editors who significantly changed their behavior upon becoming administrators. At the same time, such behavior is not rampant. Those who are promoted to administrator status tend to have more stable behavior than comparable groups of prolific editors. This suggests that the Adminship process works well, and that the Wikipedia community is not overwhelmed by users who become administrators to promote their own points of view.
Algorithmic Detection of Computer Generated Text
Aug 04, 2010
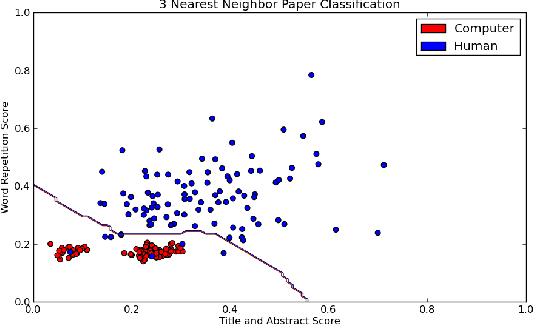
Computer generated academic papers have been used to expose a lack of thorough human review at several computer science conferences. We assess the problem of classifying such documents. After identifying and evaluating several quantifiable features of academic papers, we apply methods from machine learning to build a binary classifier. In tests with two hundred papers, the resulting classifier correctly labeled papers either as human written or as computer generated with no false classifications of computer generated papers as human and a 2% false classification rate for human papers as computer generated. We believe generalizations of these features are applicable to similar classification problems. While most current text-based spam detection techniques focus on the keyword-based classification of email messages, a new generation of unsolicited computer-generated advertisements masquerade as legitimate postings in online groups, message boards and social news sites. Our results show that taking the formatting and contextual clues offered by these environments into account may be of central importance when selecting features with which to identify such unwanted postings.