 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Detection of Computer Generated Text
Aug 04, 2010
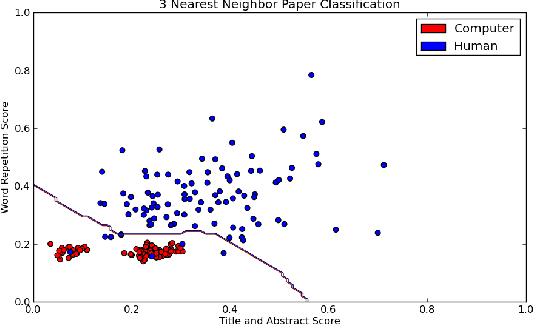
Computer generated academic papers have been used to expose a lack of thorough human review at several computer science conferences. We assess the problem of classifying such documents. After identifying and evaluating several quantifiable features of academic papers, we apply methods from machine learning to build a binary classifier. In tests with two hundred papers, the resulting classifier correctly labeled papers either as human written or as computer generated with no false classifications of computer generated papers as human and a 2% false classification rate for human papers as computer generated. We believe generalizations of these features are applicable to similar classification problems. While most current text-based spam detection techniques focus on the keyword-based classification of email messages, a new generation of unsolicited computer-generated advertisements masquerade as legitimate postings in online groups, message boards and social news sites. Our results show that taking the formatting and contextual clues offered by these environments into account may be of central importance when selecting features with which to identify such unwanted postings.