 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Tree Learning with Ordered Neurons: What Parses Does It Produce?
Paper and Code

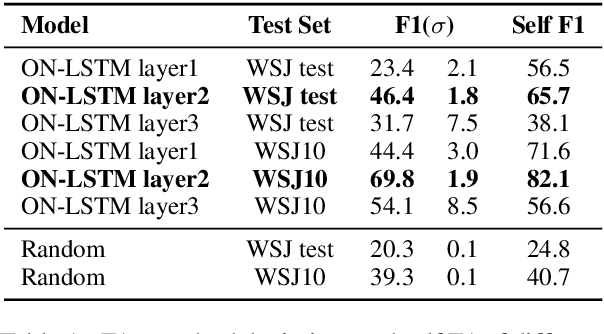
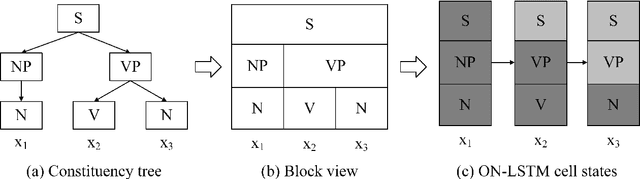
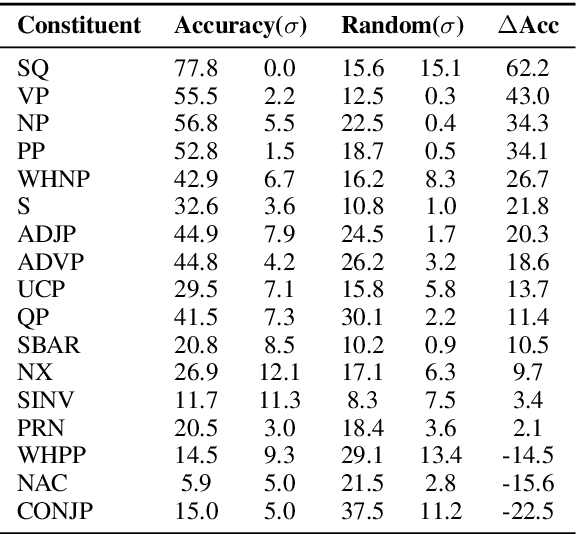
Recent latent tree learning models can learn constituency parsing without any exposure to human-annotated tree structures. One such model is ON-LSTM (Shen et al., 2019), which is trained on language modelling and has near-state-of-the-art performance on unsupervised parsing. In order to better understand the performance and consistency of the model as well as how the parses it generates are different from gold-standard PTB parses, we replicate the model with different restarts and examine their parses. We find that (1) the model has reasonably consistent parsing behaviors across different restarts, (2) the model struggles with the internal structures of complex noun phrases, (3) the model has a tendency to overestimate the height of the split points right before verbs. We speculate that both problems could potentially be solved by adopting a different training task other than unidirectional language modelling.