 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnect, Not Collapse: Explaining Contrastive Learning for Unsupervised Domain Adaptation
Paper and Code
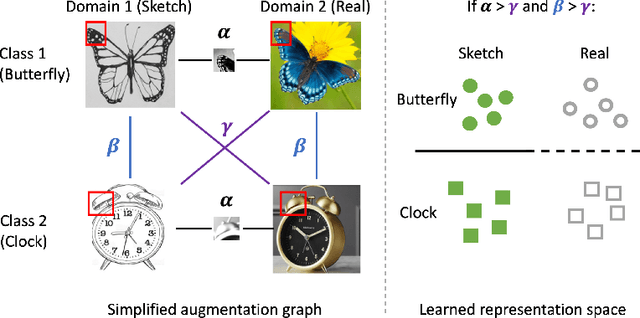
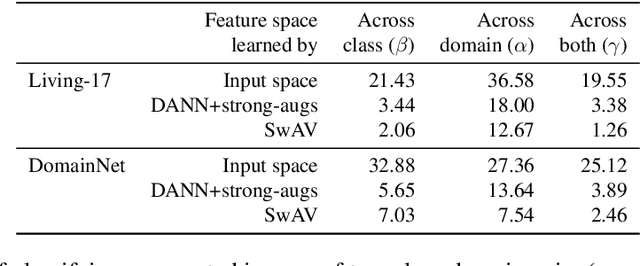
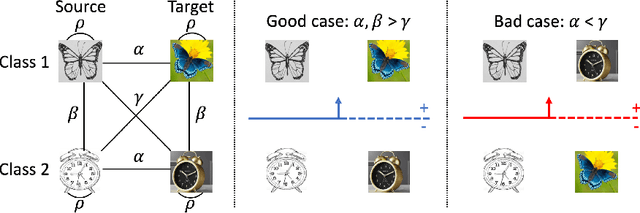

We consider unsupervised domain adaptation (UDA), where labeled data from a source domain (e.g., photographs) and unlabeled data from a target domain (e.g., sketches) are used to learn a classifier for the target domain. Conventional UDA methods (e.g., domain adversarial training) learn domain-invariant features to improve generalization to the target domain. In this paper, we show that contrastive pre-training, which learns features on unlabeled source and target data and then fine-tunes on labeled source data, is competitive with strong UDA methods. However, we find that contrastive pre-training does not learn domain-invariant features, diverging from conventional UDA intuitions. We show theoretically that contrastive pre-training can learn features that vary subtantially across domains but still generalize to the target domain, by disentangling domain and class information. Our results suggest that domain invariance is not necessary for UDA. We empirically validate our theory on benchmark vision datasets.