 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Designing Quantum Experiments with Language Models
Jun 04, 2024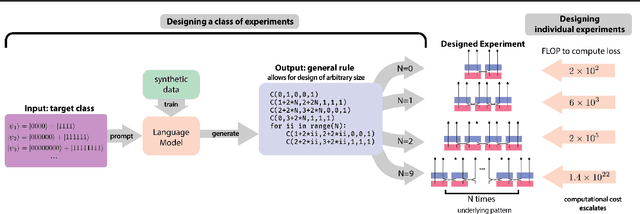


Artificial Intelligence (AI) has the potential to significantly advance scientific discovery by finding solutions beyond human capabilities. However, these super-human solutions are often unintuitive and require considerable effort to uncover underlying principles, if possible at all. Here, we show how a code-generating language model trained on synthetic data can not only find solutions to specific problems but can create meta-solutions, which solve an entire class of problems in one shot and simultaneously offer insight into the underlying design principles. Specifically, for the design of new quantum physics experiments, our sequence-to-sequence transformer architecture generates interpretable Python code that describes experimental blueprints for a whole class of quantum systems. We discover general and previously unknown design rules for infinitely large classes of quantum states. The ability to automatically generate generalized patterns in readable computer code is a crucial step toward machines that help discover new scientific understanding -- one of the central aims of physics.
Insights into Pre-training via Simpler Synthetic Tasks
Jun 21, 2022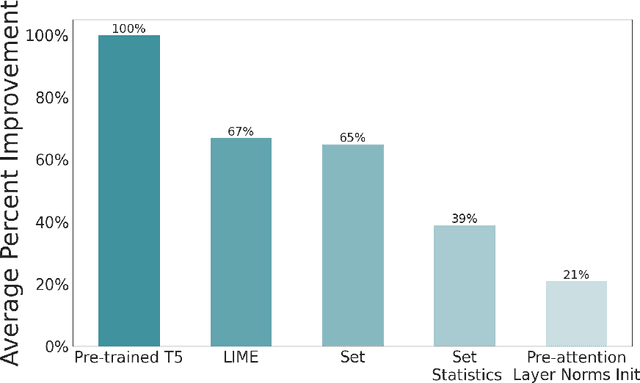
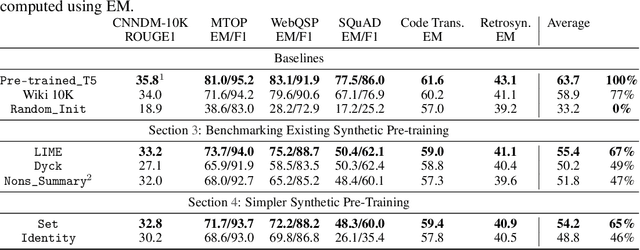
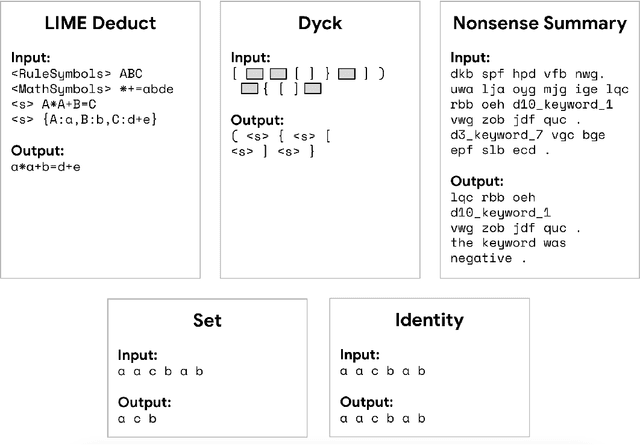
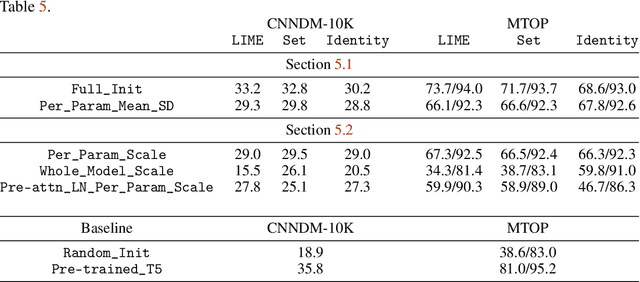
Pre-training produces representations that are effective for a wide range of downstream tasks, but it is still unclear what properties of pre-training are necessary for effective gains. Notably, recent work shows that even pre-training on synthetic tasks can achieve significant gains in downstream tasks. In this work, we perform three experiments that iteratively simplify pre-training and show that the simplifications still retain much of its gains. First, building on prior work, we perform a systematic evaluation of three existing synthetic pre-training methods on six downstream tasks. We find the best synthetic pre-training method, LIME, attains an average of $67\%$ of the benefits of natural pre-training. Second, to our surprise, we find that pre-training on a simple and generic synthetic task defined by the Set function achieves $65\%$ of the benefits, almost matching LIME. Third, we find that $39\%$ of the benefits can be attained by using merely the parameter statistics of synthetic pre-training. We release the source code at https://github.com/felixzli/synthetic_pretraining.
On-Policy Robot Imitation Learning from a Converging Supervisor
Jul 08, 2019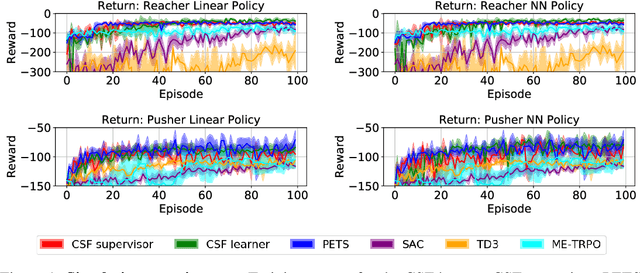


Existing on-policy imitation learning algorithms, such as DAgger, assume access to a fixed supervisor. However, there are many settings where the supervisor may converge during policy learning, such as a human performing a novel task or an improving algorithmic controller. We formalize imitation learning from a "converging supervisor" and provide sublinear static and dynamic regret guarantees against the best policy in hindsight with labels from the converged supervisor, even when labels during learning are only from intermediate supervisors. We then show that this framework is closely connected to a recent class of reinforcement learning (RL) algorithms known as dual policy iteration (DPI), which alternate between training a reactive learner with imitation learning and a model-based supervisor with data from the learner. Experiments suggest that when this framework is applied with the state-of-the-art deep model-based RL algorithm PETS as an improving supervisor, it outperforms deep RL baselines on continuous control tasks and provides up to an 80-fold speedup in policy evaluation.
Extending Deep Model Predictive Control with Safety Augmented Value Estimation from Demonstrations
Jun 03, 2019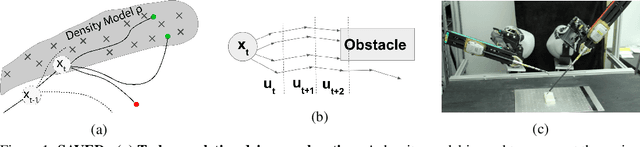
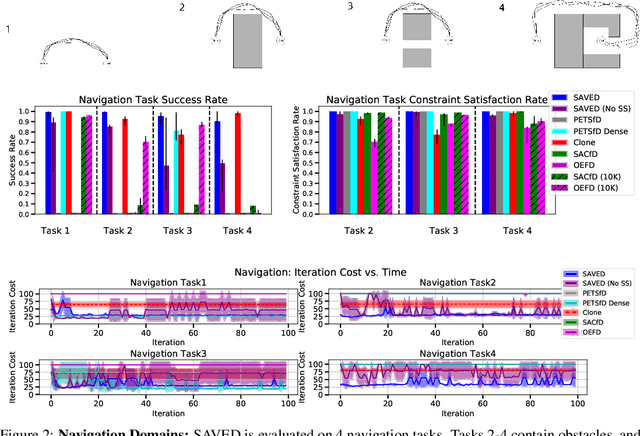

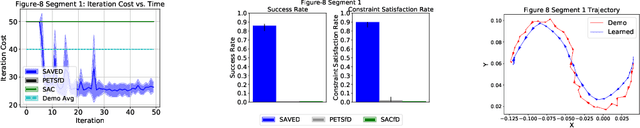
Reinforcement learning (RL) for robotics is challenging due to the difficulty in hand-engineering a dense cost function, which can lead to unintended behavior, and dynamical uncertainty, which makes it hard to enforce constraints during learning. We address these issues with a new model-based reinforcement learning algorithm, safety augmented value estimation from demonstrations (SAVED), which uses supervision that only identifies task completion and a modest set of suboptimal demonstrations to constrain exploration and learn efficiently while handling complex constraints. We derive iterative improvement guarantees for SAVED under known stochastic nonlinear systems. We then compare SAVED with 3 state-of-the-art model-based and model-free RL algorithms on 6 standard simulation benchmarks involving navigation and manipulation and 2 real-world tasks on the da Vinci surgical robot. Results suggest that SAVED outperforms prior methods in terms of success rate, constraint satisfaction, and sample efficiency, making it feasible to safely learn complex maneuvers directly on a real robot in less than an hour. For tasks on the robot, baselines succeed less than 5% of the time while SAVED has a success rate of over 75% in the first 50 training iterations.