 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights into Pre-training via Simpler Synthetic Tasks
Paper and Code
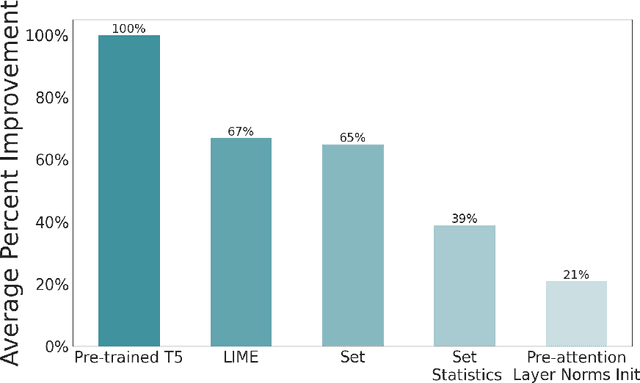
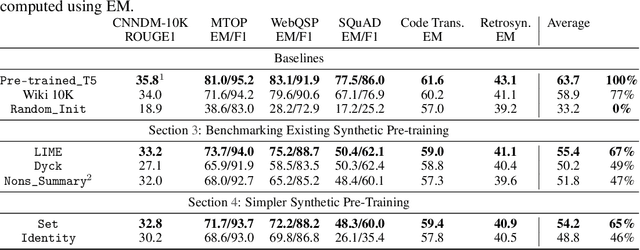
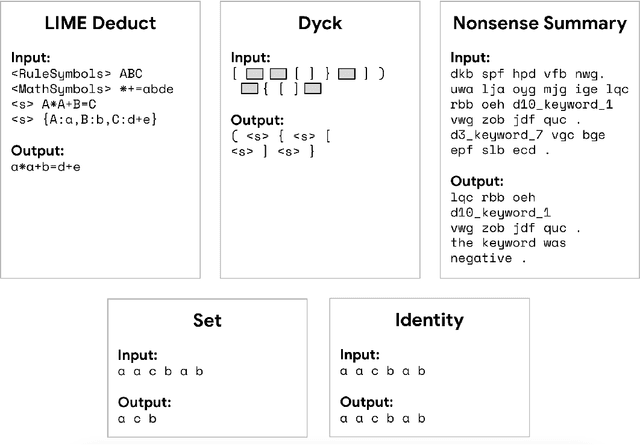
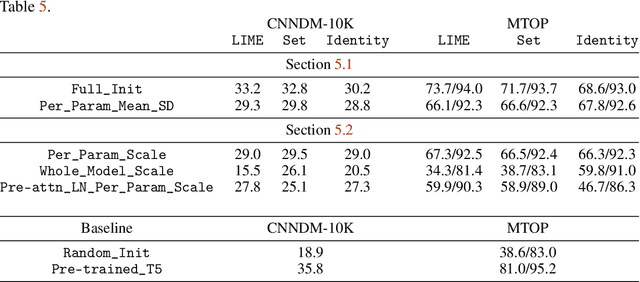
Pre-training produces representations that are effective for a wide range of downstream tasks, but it is still unclear what properties of pre-training are necessary for effective gains. Notably, recent work shows that even pre-training on synthetic tasks can achieve significant gains in downstream tasks. In this work, we perform three experiments that iteratively simplify pre-training and show that the simplifications still retain much of its gains. First, building on prior work, we perform a systematic evaluation of three existing synthetic pre-training methods on six downstream tasks. We find the best synthetic pre-training method, LIME, attains an average of $67\%$ of the benefits of natural pre-training. Second, to our surprise, we find that pre-training on a simple and generic synthetic task defined by the Set function achieves $65\%$ of the benefits, almost matching LIME. Third, we find that $39\%$ of the benefits can be attained by using merely the parameter statistics of synthetic pre-training. We release the source code at https://github.com/felixzli/synthetic_pretraining.